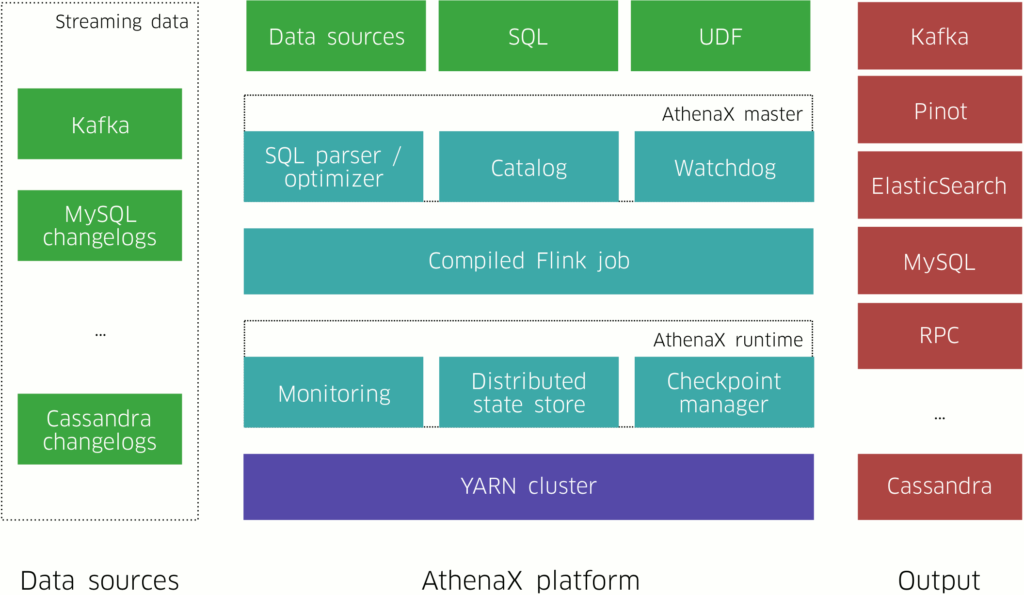
apache commons에 CircularFifoBuffer 클래스가 있다.
첫번째 예시 코드이다.
object Test extends App {
import org.apache.commons.collections.buffer.CircularFifoBuffer
val tasks = new CircularFifoBuffer(10)
tasks.add(1)
tasks.add(2)
tasks.add(5)
tasks.add(6)
println("max size : " + tasks.maxSize)
println("size: " + tasks.size)
println("--get")
println(tasks.get())
println(tasks.get())
println(tasks.get())
println(tasks.get())
println("--remove")
println(tasks.remove)
println(tasks.remove)
println(tasks.remove)
println(tasks.remove)
println("-- error")
println(tasks.remove)
}
가지고 있는 buffer보다 더 많이 remove하면 exception이 발생한다.
get을 호출하면 계속 첫번째 엘리먼트를 리턴한다. 현재 값 확인할 때 좋을 듯 하다.
max size : 10
size: 4
--get
1
1
1
1
--remove
1
2
5
6
at org.apache.commons.collections.buffer.BoundedFifoBuffer.remove(BoundedFifoBuffer.java:275)
두 번째 예시 코드이다.
object Test extends App {
import org.apache.commons.collections.buffer.CircularFifoBuffer
val tasks = new CircularFifoBuffer(10)
tasks.add(1)
tasks.add(2)
tasks.add(3)
tasks.add(4)
tasks.add(5)
tasks.add(6)
tasks.add(7)
tasks.add(8)
tasks.add(9)
tasks.add(10)
tasks.add(11)
tasks.add(12)
println("max size : " + tasks.maxSize)
println("size: " + tasks.size)
for(i <- tasks.toArray) {
println(tasks.remove)
}
}
데이터를 계속 추가하면 처음에 들어온 데이터는 삭제된다. overflow가 발생되지 않는다.
max size : 10
size: 10
3
4
5
6
7
8
9
10
11
12
'general java' 카테고리의 다른 글
| okhttp의 기본 connection pool 개수 - 5개 (0) | 2018.01.30 |
|---|---|
| [java] 진짜 쓸만한 json parser (0) | 2017.11.30 |
| jenkins 반복 job 만들기 - job dsl plugin 추천 (0) | 2017.11.01 |
| jenkins pipeline 플러그인 장점 (0) | 2017.11.01 |
| [링크] java8 stream 사용시 주의할 점 (0) | 2017.11.01 |