nosql
프레스토 소개 (facebook presto)
'김용환'
2015. 11. 5. 21:19
hive가 다 좋은데, 성능이 너무 느려서 힘들었다. 과거에 로그를 찾기 위해 hive로 고생한 것 생각하면....ㅠㅠ
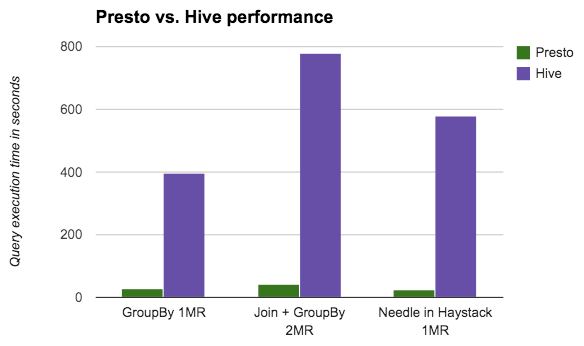
(출처 : blog.netflix.com)
hive보다 좋은 페이스북에서 SQL쿼리 엔진를 프레스토를 간략하게 소개한다.
설치 방법
설치는 presto coordinator와 worker로 나눠서 설치한다.
프레스토 아키텍처로 좋은 그림은 딱 아래와 같다. 프레스토는 coordinator와 여러 대의 worker로 나누어진다. interface역할을 coordinator가 한다.
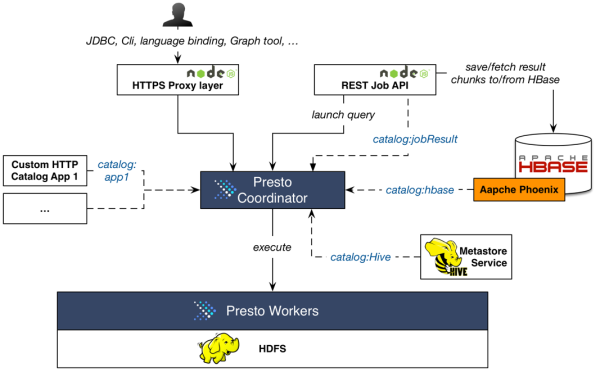
프레스토의 내부 아키텍처는 다음과 같다. connector plugin을 이용하여 어떠한 storage도 붙을 수 있다.
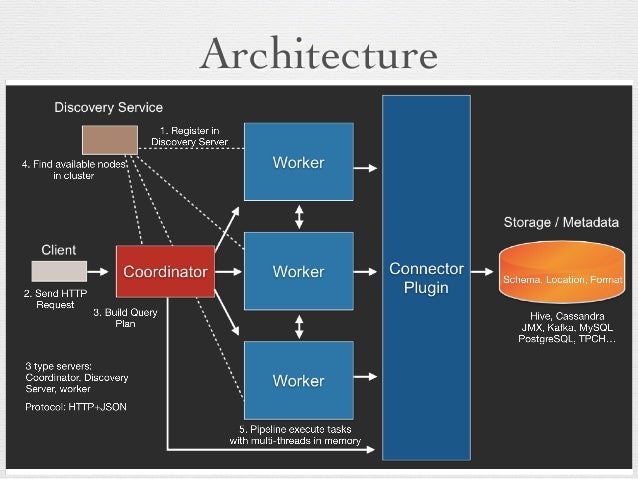
(출처 : slideshare)
써보니. Hive보다 진짜 빠르다. 대신 그 만큼 cpu와 메모리 자원을 많이 쓴다.
worker는 정말 좋은 서버로 구축해야 하며, hadoop에도 cpu 자원을 많이 쓰니, 조금 sql 문에 신경써야 한다.
presto 사용시 바로 hadoop 을 쓰는 것보다 presto에서 바로 쓸 수 있는 특정 파일시스템(ORC, Parquet)을 써야 성능이 잘 나온다고 한다. (실제로도 빠르다.)

아래는 공부하기에 좋은 자료.
http://pt.slideshare.net/GuorongLIANG/facebook-presto-presentation
https://code.facebook.com/posts/370832626374903/even-faster-data-at-the-speed-of-presto-orc/
http://techblog.netflix.com/2014/10/using-presto-in-our-big-data-platform.html