스파크 (spark) join은 두가지 전략이 있다.
셔플 조인(shuffle join)과 브로드 캐스트 조인(broadcast join)이 있다.
이 기반에는 wide dependency와 narrow dependency가 있다. 즉 최대한 driver와 executor 간 데이터 교환의 차이를 설명한 것으로서 개발 코드에 따라 성능이 달라진다.
(https://knight76.tistory.com/entry/spark-%ED%8E%8C%EC%A7%88-wide-dependecy-narrow-dependency)
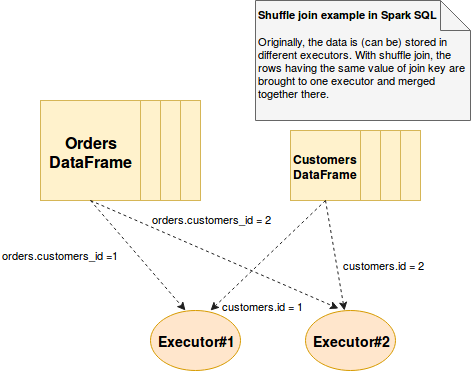
셔플 조인은 조인된 데이터를 동일한 executor로 이동하기 위해 셔플 연산을 사용한다. 각 로우를 해시로 표현 및 생성한 후 적절한 장소에 보낸다. 따라서 데이터 이동이 많이 발생한다. 내부적으로 merge sort join보다 더 많은 비용이 드는 해싱을 사용한다.
따라서 join시 데이터 흐름이 narrow해지고 executor간의 데이터 복사 비용으로 속도가 떨어지게 된다.

브로드캐스트 조인은 데이터를 executor로 복사하지만, executor간에 데이터복사가 일어나지 않기 때문에 속도가 빨라질 수 있다.
(사실 정확하게 말하면, 데이터의 양/join에 따라 브로드캐스트 조인이 좋을지, 셔플 조인이 좋을지는 테스트해봐야 한다. 이를 위해 spark sql optimizer가 그걸 내부적으로 결정하기도 한다)

아래 코드는 Spark Definitve Guide의 예제 코드인데, explain으로 어떤 조인이 사용되었는지 알 수 있다.
package spark.example.tutorial.chapter08
import spark.example.common.SparkHelper
object JoinMain extends SparkHelper {
def main(args: Array[String]): Unit = {
import spark.implicits._
val person = Seq(
(0, "Bill Chaambers", 0, Seq(100)),
(1, "Matei Zaharia", 1, Seq(500, 250, 100)),
(2, "Michael Armbrust", 1, Seq(250, 100)))
.toDF("id", "name", "graduate_program", "spark_status")
val graduateProgram = Seq(
(0, "Masters", "School of Information", "UC Berkeley"),
(2, "Masters", "EECS", "UC Berkeley"),
(1, "Ph.D.", "EECS", "UC Berkeley"))
.toDF("id", "degree", "department", "school")
person.createOrReplaceTempView("person")
graduateProgram.createOrReplaceTempView("graduateProgram")
val joinExpr1 = person.col("graduate_program") === graduateProgram.col("id")
person.join(graduateProgram, joinExpr1).explain()
import org.apache.spark.sql.functions.broadcast
val joinExpr2 = person.col("graduate_program") === graduateProgram.col("id")
person.join(broadcast(graduateProgram), joinExpr2).explain()
}
}
보면 둘다 broadcast join이다. spark 내부 optimizer가 힌트를 주든 안주든 내부적으로 broadcast 조인을 할 수 있게 되었다.
== Physical Plan ==
*(1) BroadcastHashJoin [graduate_program#11], [id#26], Inner, BuildLeft
:- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[2, int, false] as bigint)))
: +- LocalTableScan [id#9, name#10, graduate_program#11, spark_status#12]
+- LocalTableScan [id#26, degree#27, department#28, school#29]
== Physical Plan ==
*(1) BroadcastHashJoin [graduate_program#11], [id#26], Inner, BuildRight
:- LocalTableScan [id#9, name#10, graduate_program#11, spark_status#12]
+- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint)))
+- LocalTableScan [id#26, degree#27, department#28, school#29]
관련 내용은 참조글은 아래 글을 기반으로 한다.
https://www.waitingforcode.com/apache-spark-sql/shuffle-join-spark-sql/read
https://henning.kropponline.de/2016/12/11/broadcast-join-with-spark/
'scala' 카테고리의 다른 글
| [spark] No output operations registered, so nothing to execute 에러 (0) | 2019.04.03 |
|---|---|
| [spark] spark에서 DB 테이블 데이터를 읽는 방법 (0) | 2019.02.28 |
| [spark] Malformed class name 에러 해결하기 (0) | 2019.02.27 |
| [spark] monotonically_increasing_id 예시 (0) | 2019.02.25 |
| [spark] requirement failed: Currently correlation calculation for columns with dataType string not supported. 해결하기; (0) | 2019.02.25 |



