다양한 정보를 바탕으로 '검색 추천어'를 개발하고 있다.
지표 정보를 read_pv, read_uv, wirte_pv, write_uv, writer_uv 로 나누어 저장하고,
각 정보에 대한 가중치를 곱해 100점 만점의 점수표로 추천 검색의 순서(rank)를 정했다.
ES + R + MariaDB + java + python(hive) 로 진행하고 있다.
추가할 부분은 Time Decay에 대한 부분인데, 특정 지표에 대해서는 최신 데이터일수록 높은 가중치를 주는 방식으로 변경해 보았다.
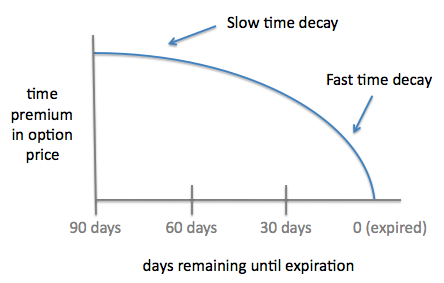
(출처: https://www.borntosell.com/covered-call-blog)
이를 위한 참조 자료로 반감기(http://egloos.zum.com/taniguchi/v/2588675)를 참고로 해서 EXP 또는 ARCTAN 또는 Log 함수로 대충 느낌을 느낌을 낼 수 있다. (그냥 대충 숫자로 가중치 주는 것이 웃긴다.) 함수로 표현하기 위해서 https://www.desmos.com/ 를 사용한다. 그래프의 저장은 구글 계정으로 인증하면 구글 드라이브로 저장을 할 수 있다.
또한 논리적인 개념이 필요하니, http://docs.likejazz.com/k-ranker/ 블로그 글을 참조하여 나름 rank 시스템을 만들어보았다. 좀 더 다듬고 남이 어떻게 하는지 좀 보고 보정 작업을 진행할 예정이다.
'scribbling' 카테고리의 다른 글
| 게임 점검 (긴급, 임시, 정기) (0) | 2015.08.22 |
|---|---|
| [펌] 월스트리트 저널의 차트 작성 비법 - 출처 (ㅍㅍㅅㅅ) (0) | 2015.08.14 |
| ~ (숫자, 단위) 이하를 영어로 (0) | 2015.07.10 |
| google place api로 자동완성/결과 검색시 언어설정과 언어 검색 내용에 의존한다. (0) | 2015.06.03 |
| [펌] 서버 하드웨어 모니터링 (0) | 2015.05.28 |



