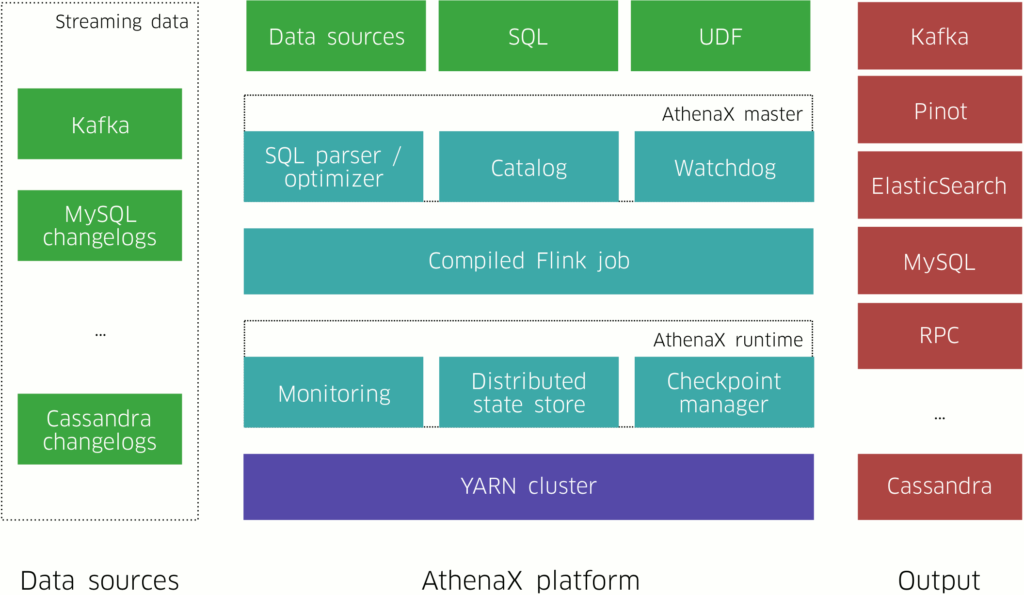
일래스틱서치의 기본 인덱스의 필드 최대 개수는 1000이다.
만약 아래와 같은 에러가 발생했다면 다음 내용을 참조한다.
Limit of total fields [1000] in index [인덱스 이름] has been exceeded.
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping.html
Settings to prevent mappings explosionedit
Defining too many fields in an index is a condition that can lead to a mapping explosion, which can cause out of memory errors and difficult situations to recover from. This problem may be more common than expected. As an example, consider a situation in which every new document inserted introduces new fields. This is quite common with dynamic mappings. Every time a document contains new fields, those will end up in the index’s mappings. This isn’t worrying for a small amount of data, but it can become a problem as the mapping grows. The following settings allow you to limit the number of field mappings that can be created manually or dynamically, in order to prevent bad documents from causing a mapping explosion:
index.mapping.total_fields.limit- The maximum number of fields in an index. The default value is
1000. index.mapping.depth.limit- The maximum depth for a field, which is measured as the number of inner objects. For instance, if all fields are defined at the root object level, then the depth is
1. If there is one object mapping, then the depth is2, etc. The default is20. index.mapping.nested_fields.limit- The maximum number of
nestedfields in an index, defaults to50. Indexing 1 document with 100 nested fields actually indexes 101 documents as each nested document is indexed as a separate hidden document.
필드 개수를 늘리는 것에 대해서 문서 뉘앙스는 bad이니 어느 정도부터는 성능 상 분명 존재할 것 같기도 하다..
굳이 변경하려면 다음과 같이 진행한다.
PUT 'localhost:9200/myindex/_settings' -d '
{
"index.mapping.total_fields.limit": 10000
}'
그러나, 될 수 있으면 조심해서 쓰라고 하니. 참고하길 바란다.
https://discuss.elastic.co/t/limit-of-total-fields-1000-in-index-has-been-exceeded/87280/2
->(Elastic Team Member) Just understand that more fields is more overhead and that sparse fields cause trouble. So raise it with caution. Bumping into the limit is likely a sign that you are doing something that isn't going to work well with Elasticsearch in the future.
'Elasticsearch' 카테고리의 다른 글
| [elasticsearch5] _id 필드 대신 _uid (0) | 2017.11.22 |
|---|---|
| [elasticsearch] No log4j2 configuration file found. Using default configuration: logging only errors to the console 에러 해결하기 (0) | 2017.11.15 |
| [일래스틱서치] “Hot-Warm” architecture - 퍼옴 (0) | 2017.09.01 |
| [elasticsearch5] dynamic template (0) | 2017.08.23 |
| [elasticsearch5] elasticsearch for hadoop(하둡 연동 일레스틱서치) (0) | 2017.08.23 |