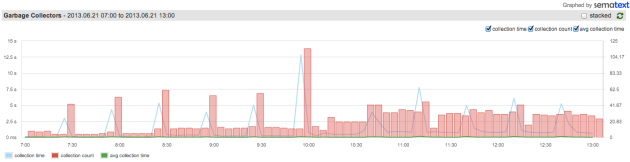
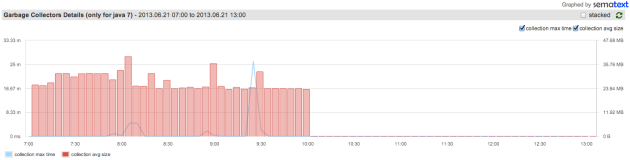
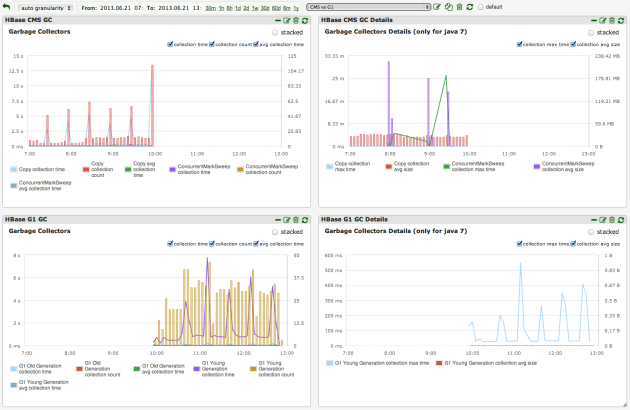
Hbase의 Chore는 일종의 Job 또는 Thread 이며 짜치는(?) 일을 Hbase에서 담당하고 있다. 생각해보면 굳이 thread 클래스를 상속받을 필요가 있겠냐마는... 사실 문제가 있다.
1. 배경
이문제는 jdk 1.6 17, jdk 7에서 패치되었지만, 그 이하의 버전에서는 deadlock 문제가 된다. 그래서 0.92.0에 Chore가 추가되었다.
HBASE-4367 , JDK 버그 6915621, HBASE-4101과 연관이 있다.
Resource Bundle 클래스에서 lock이 아래와 걸린 것을 확인할 수 있다. 내부적으로 Thread.currentThread()를 monitor lock으로 사용하면서 문제가 생긴 것이라 알려져 있다.
"IPC Server handler 37 on 60020":
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00002aaab584cee0> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:158)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:747)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(AbstractQueuedSynchronizer.java:778)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2061)
at org.apache.hadoop.hbase.regionserver.MemStoreFlusher.reclaimMemStoreMemory(MemStoreFlusher.java:444)
- locked <0x00002aaab5519648> (a org.apache.hadoop.hbase.regionserver.MemStoreFlusher)
at org.apache.hadoop.hbase.regionserver.HRegionServer.multi(HRegionServer.java:2586)
"regionserver60020.cacheFlusher":
at java.util.ResourceBundle.endLoading(ResourceBundle.java:1506)
- waiting to lock <0x00002aaab5519648> (a org.apache.hadoop.hbase.regionserver.MemStoreFlusher)
at java.util.ResourceBundle.findBundle(ResourceBundle.java:1379)
at java.util.ResourceBundle.findBundle(ResourceBundle.java:1292)
at java.util.ResourceBundle.getBundleImpl(ResourceBundle.java:1234)
at java.util.ResourceBundle.getBundle(ResourceBundle.java:832)
at sun.util.resources.LocaleData$1.run(LocaleData.java:127)
at java.security.AccessController.doPrivileged(Native Method)
at sun.util.resources.LocaleData.getBundle(LocaleData.java:125)
at sun.util.resources.LocaleData.getTimeZoneNames(LocaleData.java:97)
at sun.util.TimeZoneNameUtility.getBundle(TimeZoneNameUtility.java:115)
at sun.util.TimeZoneNameUtility.retrieveDisplayNames(TimeZoneNameUtility.java:80)
at java.util.TimeZone.getDisplayNames(TimeZone.java:399)
at java.util.TimeZone.getDisplayName(TimeZone.java:350)
at java.util.Date.toString(Date.java:1025)
at java.lang.String.valueOf(String.java:2826)
at java.lang.StringBuilder.append(StringBuilder.java:115)
at org.apache.hadoop.hbase.regionserver.PriorityCompactionQueue$CompactionRequest.toString(PriorityCompactionQueue.java:114)
at java.lang.String.valueOf(String.java:2826)
at java.lang.StringBuilder.append(StringBuilder.java:115)
at org.apache.hadoop.hbase.regionserver.PriorityCompactionQueue.addToRegionsInQueue(PriorityCompactionQueue.java:145)
- locked <0x00002aaab55aa2a8> (a java.util.HashMap)
2. Chore
http://hbase.apache.org/apidocs/org/apache/hadoop/hbase/Chore.html
@InterfaceAudience.Private
public abstract class Chore
- extends HasThread
Chore is a task performed on a period in hbase. The chore is run in its own thread. This base abstract class provides while loop and sleeping facility. If an unhandled exception, the threads exit is logged. Implementers just need to add checking if there is work to be done and if so, do it. Its the base of most of the chore threads in hbase.
Don't subclass Chore if the task relies on being woken up for something to do, such as an entry being added to a queue, etc.
설명에 있는 것처럼 다양한 짜치는(?) 작업을 진행한다. 다음은 상속받은 클래스이다.
AssignmentManager.TimeoutMonitor, AssignmentManager.TimerUpdater, BalancerChore, CatalogJanitor, CleanerChore, ClusterStatusChore,ClusterStatusPublisher, HealthCheckChore, HRegionServer.MovedRegionsCleaner
Chore의 super class인 HasThread는 다음과 같다. Thread Wrapper의 형태를 띄고 있다.
/**
* Abstract class which contains a Thread and delegates the common Thread
* methods to that instance.
*
* The purpose of this class is to workaround Sun JVM bug #6915621, in which
* something internal to the JDK uses Thread.currentThread() as a monitor
* lock. This can produce deadlocks like HBASE-4367, HBASE-4101, etc.
*/
@InterfaceAudience.Private
public abstract class HasThread implements Runnable {
private final Thread thread;
public HasThread() {
this.thread = new Thread(this);
}
public HasThread(String name) {
this.thread = new Thread(this, name);
}
public Thread getThread() {
return thread;
}
public abstract void run();
//// Begin delegation to Thread
public final String getName() {
return thread.getName();
}
public void interrupt() {
thread.interrupt();
}
public final boolean isAlive() {
return thread.isAlive();
}
public boolean isInterrupted() {
return thread.isInterrupted();
}
public final void setDaemon(boolean on) {
thread.setDaemon(on);
}
public final void setName(String name) {
thread.setName(name);
}
public final void setPriority(int newPriority) {
thread.setPriority(newPriority);
}
public void setUncaughtExceptionHandler(UncaughtExceptionHandler eh) {
thread.setUncaughtExceptionHandler(eh);
}
public void start() {
thread.start();
}
public final void join() throws InterruptedException {
thread.join();
}
public final void join(long millis, int nanos) throws InterruptedException {
thread.join(millis, nanos);
}
public final void join(long millis) throws InterruptedException {
thread.join(millis);
}
//// End delegation to Thread
}
Chore는 다음과 같다.
public abstract class Chore extends HasThread {
private final Log LOG = LogFactory.getLog(this.getClass());
private final Sleeper sleeper;
protected final Stoppable stopper;
/**
* @param p Period at which we should run. Will be adjusted appropriately
* should we find work and it takes time to complete.
* @param stopper When {@link Stoppable#isStopped()} is true, this thread will
* cleanup and exit cleanly.
*/
public Chore(String name, final int p, final Stoppable stopper) {
super(name);
if (stopper == null){
throw new NullPointerException("stopper cannot be null");
}
this.sleeper = new Sleeper(p, stopper);
this.stopper = stopper;
}
/**
* This constructor is for test only. It allows to create an object and to call chore() on
* it. There is no sleeper nor stoppable.
*/
protected Chore(){
sleeper = null;
stopper = null;
}
/**
* @see java.lang.Thread#run()
*/
@Override
public void run() {
try {
boolean initialChoreComplete = false;
while (!this.stopper.isStopped()) {
long startTime = System.currentTimeMillis();
try {
if (!initialChoreComplete) {
initialChoreComplete = initialChore();
} else {
chore();
}
} catch (Exception e) {
LOG.error("Caught exception", e);
if (this.stopper.isStopped()) {
continue;
}
}
this.sleeper.sleep(startTime);
}
} catch (Throwable t) {
LOG.fatal(getName() + "error", t);
} finally {
LOG.info(getName() + " exiting");
cleanup();
}
}
/**
* If the thread is currently sleeping, trigger the core to happen immediately.
* If it's in the middle of its operation, will begin another operation
* immediately after finishing this one.
*/
public void triggerNow() {
this.sleeper.skipSleepCycle();
}
/*
* Exposed for TESTING!
* calls directly the chore method, from the current thread.
*/
public void choreForTesting() {
chore();
}
/**
* Override to run a task before we start looping.
* @return true if initial chore was successful
*/
protected boolean initialChore() {
// Default does nothing.
return true;
}
/**
* Look for chores. If any found, do them else just return.
*/
protected abstract void chore();
/**
* Sleep for period.
*/
protected void sleep() {
this.sleeper.sleep();
}
/**
* Called when the chore has completed, allowing subclasses to cleanup any
* extra overhead
*/
protected void cleanup() {
}
}
예를 들어 간단히 BalancerChore를 보면 hbase.balancer.period값을 읽어 그 주기 마다 HMaster의 balance() 메소드를 호출하도록 되어 있다.
Chore는 HasThread를 상속하고, Stoppable interface를 받아 Sleeper를 구현했다. 어떤 조건에 따라 Thread를 통제하도록 코딩되어 있다.
public abstract class Chore extends HasThread {
private final Log LOG = LogFactory.getLog(this.getClass());
private final Sleeper sleeper;
protected final Stoppable stopper;
public Chore(String name, final int p, final Stoppable stopper) {
super(name);
if (stopper == null){
throw new NullPointerException("stopper cannot be null");
}
this.sleeper = new Sleeper(p, stopper);
this.stopper = stopper;
}
protected Chore(){
sleeper = null;
stopper = null;
}
@Override
public void run() {
try {
boolean initialChoreComplete = false;
while (!this.stopper.isStopped()) {
long startTime = System.currentTimeMillis();
try {
if (!initialChoreComplete) {
initialChoreComplete = initialChore();
} else {
chore();
}
} catch (Exception e) {
LOG.error("Caught exception", e);
if (this.stopper.isStopped()) {
continue;
}
}
this.sleeper.sleep(startTime);
}
} catch (Throwable t) {
LOG.fatal(getName() + "error", t);
} finally {
LOG.info(getName() + " exiting");
cleanup();
}
}
public void triggerNow() {
this.sleeper.skipSleepCycle();
}
public void choreForTesting() {
chore();
}
protected boolean initialChore() {
// Default does nothing.
return true;
}
protected abstract void chore();
protected void sleep() {
this.sleeper.sleep();
}
protected void cleanup() {
}
}
그리고. CleanChore를 상속받은 LogCleaner는 다음과 같다.
/**
* This Chore, every time it runs, will attempt to delete the HLogs in the old logs folder. The HLog
* is only deleted if none of the cleaner delegates says otherwise.
* @see BaseLogCleanerDelegate
*/
@InterfaceAudience.Private
public class LogCleaner extends CleanerChore<BaseLogCleanerDelegate> {
static final Log LOG = LogFactory.getLog(LogCleaner.class.getName());
/**
* @param p the period of time to sleep between each run
* @param s the stopper
* @param conf configuration to use
* @param fs handle to the FS
* @param oldLogDir the path to the archived logs
*/
public LogCleaner(final int p, final Stoppable s, Configuration conf, FileSystem fs,
Path oldLogDir) {
super("LogsCleaner", p, s, conf, fs, oldLogDir, HBASE_MASTER_LOGCLEANER_PLUGINS);
}
@Override
protected boolean validate(Path file) {
return HLogUtil.validateHLogFilename(file.getName());
}
}
좀더 재미있는 Chore는 HealthCheckChore가 될 것이다. 특정 스크립트의 timeout를 조절도 가능하다.
public class HealthCheckChore extends Chore {
private static Log LOG = LogFactory.getLog(HealthCheckChore.class);
private HealthChecker healthChecker;
private Configuration config;
private int threshold;
private int numTimesUnhealthy = 0;
private long failureWindow;
private long startWindow;
public HealthCheckChore(int sleepTime, Stoppable stopper, Configuration conf) {
super("HealthChecker", sleepTime, stopper);
LOG.info("Health Check Chore runs every " + StringUtils.formatTime(sleepTime));
this.config = conf;
String healthCheckScript = this.config.get(HConstants.HEALTH_SCRIPT_LOC);
long scriptTimeout = this.config.getLong(HConstants.HEALTH_SCRIPT_TIMEOUT,
HConstants.DEFAULT_HEALTH_SCRIPT_TIMEOUT);
healthChecker = new HealthChecker();
healthChecker.init(healthCheckScript, scriptTimeout);
this.threshold = config.getInt(HConstants.HEALTH_FAILURE_THRESHOLD,
HConstants.DEFAULT_HEALTH_FAILURE_THRESHOLD);
this.failureWindow = (long)this.threshold * (long)sleepTime;
}
@Override
protected void chore() {
HealthReport report = healthChecker.checkHealth();
boolean isHealthy = (report.getStatus() == HealthCheckerExitStatus.SUCCESS);
if (!isHealthy) {
boolean needToStop = decideToStop();
if (needToStop) {
this.stopper.stop("The node reported unhealthy " + threshold
+ " number of times consecutively.");
}
// Always log health report.
LOG.info("Health status at " + StringUtils.formatTime(System.currentTimeMillis()) + " : "
+ report.getHealthReport());
}
}
private boolean decideToStop() {
boolean stop = false;
if (numTimesUnhealthy == 0) {
// First time we are seeing a failure. No need to stop, just
// record the time.
numTimesUnhealthy++;
startWindow = System.currentTimeMillis();
} else {
if ((System.currentTimeMillis() - startWindow) < failureWindow) {
numTimesUnhealthy++;
if (numTimesUnhealthy == threshold) {
stop = true;
} else {
stop = false;
}
} else {
// Outside of failure window, so we reset to 1.
numTimesUnhealthy = 1;
startWindow = System.currentTimeMillis();
stop = false;
}
}
return stop;
}
}