hashMap을 사용하는 곳에서 cpu를 많이 소요하는 부분이 발견되었다.
1. freemarker 예제
"TP-Processor215" daemon prio=10 tid=0x55476000 nid=0xfab runnable [0x5495c000]
java.lang.Thread.State: RUNNABLE
at java.util.HashMap.get(HashMap.java:303)
at freemarker.core.RegexBuiltins.getPattern(RegexBuiltins.java:77)
at freemarker.core.RegexBuiltins$MatcherBuilder.exec(RegexBuiltins.java:277)
at freemarker.core.MethodCall._getAsTemplateModel(MethodCall.java:93)
at freemarker.core.Expression.getAsTemplateModel(Expression.java:89)
at freemarker.core.Expression.isTrue(Expression.java:138)
"TP-Processor61" daemon prio=10 tid=0x08fe5800 nid=0x35f9 runnable [0x52575000]
java.lang.Thread.State: RUNNABLE
at java.util.HashMap.get(HashMap.java:303)
at freemarker.core.RegexBuiltins.getPattern(RegexBuiltins.java:77)
at freemarker.core.RegexBuiltins$MatcherBuilder.exec(RegexBuiltins.java:277)
at freemarker.core.MethodCall._getAsTemplateModel(MethodCall.java:93)
at freemarker.core.Expression.getAsTemplateModel(Expression.java:89)
at freemarker.core.Expression.isTrue(Expression.java:138)
at freemarker.core.NotExpression.isTrue(NotExpression.java:66)
at freemarker.core.ParentheticalExpression.isTrue(ParentheticalExpression.java:66)
at freemarker.core.ConditionalBlock.accept(ConditionalBlock.java:77)
at freemarker.core.Environment.visit(Environment.java:208)
at freemarker.core.MixedContent.accept(MixedContent.java:92)
at freemarker.core.Environment.visit(Environment.java:208)
at freemarker.core.IfBlock.accept(IfBlock.java:82)
2. 사용자 개발 코드에서 hashmap 사용
java.lang.Thread.State: RUNNABLE
at java.util.HashMap.put(HashMap.java:374)
둘다 HashMap을 사용한 것인데..
아래 beautiful race condtion이라는 블로그에서 hashmap을 사용하면서 문제가 있을만한 부분을 소개했다.
http://mailinator.blogspot.com/2009/06/beautiful-race-condition.html
간단하게 말하면..
Thread1과 Thread2가 resize() 메소드로 들어왔는데..Thread1 이 한 중간에 멈추어졌고, Thread2는 resize를 한 경우에 생길 수 있는 부분을 설명하였다..
2: // called to resize the hashmap
3:
4: for (int j = 0; j < src.length; j++) {
5: Entry
6: if (e != null) {
7: src[j] = null;
8: do {
9: Entry
// Thread1 STOPS RIGHT HERE
10: int i = indexFor(e.hash, newCapacity);
11: e.next = newTable[i];
12: newTable[i] = e;
13: e = next;
14: } while (e != null);
15: }
16: }
Thread 1이 resize 메소드의 9줄까지 실행했다고 가정.
 Thread2는 resize 메소드를 다 실행하였다.
Thread2는 resize 메소드를 다 실행하였다.

즉, A-> B를 가르키고, 있고, B->A를 가르키는 상태이다.
Thread1이 처리를 완료하면서.A-><-B가 되면서..

map에 저장되던 데이터들이 cross refererence되어서 무한 루프에 걸리는 현상이 발견되었다.
HashMap의 get, put 메소드를 본다.
즉, entry가 null일 때까지 for문을 돌릴 수 밖에 없는 구조이기 때문에, 계속 돌아가는 구조이다.
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
addEntry(hash, key, value, i);
return null;
}
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
따라서, HashMap은 동기화 문제가 발생될 수 있는 곳에 사용해서는 안된다. 차라리 ConcurrentHashMap을 쓰는 것이 맞다. 그게 싫다면, HashMap을 쓸 떄, 프레임웍을 쓰든, 잘 사용하면 좋을 수도 있겠다.
Synchronized hashmap 과 ConcurrentHashMap의 성능에 대한 블로그가 있다.
http://unserializableone.blogspot.com/2007/04/performance-comparision-between.html
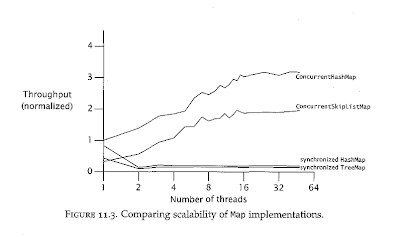

요즘에. Apache Common 개발자들이 synchronized HashMap보다는 ConcurrentHashMap을 더 많이 사용하려는 움직임이 있다.
https://issues.apache.org/jira/browse/HTTPCLIENT-903
http://www.mail-archive.com/dev@commons.apache.org/msg18926.html
@comment
ConcurrentHashMap이 SynchronizedHashMap보다 성능이 훨씬 좋거나. 비슷하다. 따라서, ConcurrentHashMap 에 대한 성능차이가 거의 없다면 써도 무방하지 않을까 생각이 든다.
'java core' 카테고리의 다른 글
| jdk contant value 모음 (0) | 2011.02.08 |
|---|---|
| jdbc specification 보기 (0) | 2011.02.07 |
| OOME 검출 방법 (0) | 2011.01.06 |
| vebose:gc 를 파일 로그로 남기기 (0) | 2010.11.22 |
| 안드로이드 코딩 가이드 중 Designing for Performance (0) | 2010.10.04 |



