MSLAB (MemStore-Local Allocation Buffers, http://knight76.tistory.com/entry/hbase-MSLAB-MemStoreLocal-Allocation-Buffer-공부) 는 Hbase의 write buffer인 mem store기반위에 byte[]를 이용하여 구현했다.
반면, Hbase의 read buffer인 block cache인 여러 구현체를 잘 사용함으로서, read성능을 최대로 낼 수 있다.
LruBlockCache가 대표적이긴 하지만 BucketCache, SlabCache(SingleSizeCache), SimpleBlockCache, BucketCache와 LruBlockCache를 섞어놓은 CombinedBlockCache, LruBlockCache와 SlabCache을 섞어놓은 DoubleBlockCache 등이 있어 다양하게 적용해볼 수 있다.
LruBlockCache는 java heap을 쓰기 때문에 gc 이슈가 크다는 단점이 있다. 이를 위한 튜닝이 필수적이다. 디폴트로 heap의 25%을 지정하도록 되어 있다. 파편화를 줄이기 위해서 fixed된 메모리를 사용하는 SlabCache를 사용할 수 있지만, Slab memory를 사용하는 나름의 단점(get/cache시 memory copy)이 있다.
Buckcache는 캐쉬 공간을 라벨링을 할 수 있고, size를 지정할 수 있는 bucket으로 나누어 캐쉬를 관리할 수 있다.
사용자가 어떤 CacheBlock을 쓸 것인지 결정하기 위해서는 문서가 없어서 소스를 참조해야 했다. CacheConfig 클래스를 참조해야 한다. 13번, 14번을 참조하면 된다.
2013.6.7일에 작성된 것으로 해당 링크를 기준으로 작성되었다. 설정 데이터의 경우가 코드가 빠르게 진행되는터라, 문서에는 늦게 반영되는 듯 하다.
0. Block 소개
Block은 DataBlock (64K, storage K-V), BloomBlock(128K, storage BloomFilter data), IndexBlock(128K, index datat) 로 구성되어 있다. BloomBlock과 IndexBlock은 거의 100% 사용하기 때문에 MetaBlock이라 불린다. 캐쉬된 block을 Block Cache라 하고, read performance를 위해 존재한다.
1. read & write buffer
http://nosql.mypopescu.com/post/18943894052/what-hbase-learned-from-the-hypertable-vs-hbase
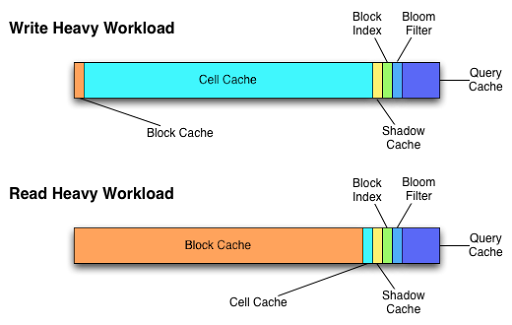
2. http://hbase.apache.org/book/config.files.html
hfile.block.cache.sizePercentage of maximum heap (-Xmx setting) to allocate to block cache used by HFile/StoreFile. Default of 0.25 means allocate 25%. Set to 0 to disable but it's not recommended.
Default: 0.25
hbase.rs.cacheblocksonwriteWhether an HFile block should be added to the block cache when the block is finished.
Default: false
hfile.block.index.cacheonwriteThis allows to put non-root multi-level index blocks into the block cache at the time the index is being written.
Default: false
hfile.block.bloom.cacheonwriteEnables cache-on-write for inline blocks of a compound Bloom filter.
Default: false
3. http://hbase.apache.org/book/important_configurations.html
2.5.3.2. Disabling Blockcache
Do not turn off block cache (You'd do it by setting hbase.block.cache.size to zero). Currently we do not do well if you do this because the regionserver will spend all its time loading hfile indices over and over again. If your working set it such that block cache does you no good, at least size the block cache such that hfile indices will stay up in the cache (you can get a rough idea on the size you need by surveying regionserver UIs; you'll see index block size accounted near the top of the webpage).
4.http://hbase.apache.org/book/regionserver.arch.html
9.6.4. Block Cache
The Block Cache is an LRU cache that contains three levels of block priority to allow for scan-resistance and in-memory ColumnFamilies:
- Single access priority: The first time a block is loaded from HDFS it normally has this priority and it will be part of the first group to be considered during evictions. The advantage is that scanned blocks are more likely to get evicted than blocks that are getting more usage.
- Mutli access priority: If a block in the previous priority group is accessed again, it upgrades to this priority. It is thus part of the second group considered during evictions.
- In-memory access priority: If the block's family was configured to be "in-memory", it will be part of this priority disregarding the number of times it was accessed. Catalog tables are configured like this. This group is the last one considered during evictions.
For more information, see the LruBlockCache source
Block caching is enabled by default for all the user tables which means that any read operation will load the LRU cache. This might be good for a large number of use cases, but further tunings are usually required in order to achieve better performance. An important concept is the working set size, or WSS, which is: "the amount of memory needed to compute the answer to a problem". For a website, this would be the data that's needed to answer the queries over a short amount of time.
The way to calculate how much memory is available in HBase for caching is:
number of region servers * heap size * hfile.block.cache.size * 0.85
The default value for the block cache is 0.25 which represents 25% of the available heap. The last value (85%) is the default acceptable loading factor in the LRU cache after which eviction is started. The reason it is included in this equation is that it would be unrealistic to say that it is possible to use 100% of the available memory since this would make the process blocking from the point where it loads new blocks. Here are some examples:
- One region server with the default heap size (1GB) and the default block cache size will have 217MB of block cache available.
- 20 region servers with the heap size set to 8GB and a default block cache size will have 34GB of block cache.
- 100 region servers with the heap size set to 24GB and a block cache size of 0.5 will have about 1TB of block cache.
Your data isn't the only resident of the block cache, here are others that you may have to take into account:
- Catalog tables: The -ROOT- and .META. tables are forced into the block cache and have the in-memory priority which means that they are harder to evict. The former never uses more than a few hundreds of bytes while the latter can occupy a few MBs (depending on the number of regions).
- HFiles indexes: HFile is the file format that HBase uses to store data in HDFS and it contains a multi-layered index in order seek to the data without having to read the whole file. The size of those indexes is a factor of the block size (64KB by default), the size of your keys and the amount of data you are storing. For big data sets it's not unusual to see numbers around 1GB per region server, although not all of it will be in cache because the LRU will evict indexes that aren't used.
- Keys: Taking into account only the values that are being stored is missing half the picture since every value is stored along with its keys (row key, family, qualifier, and timestamp). SeeSection 6.3.2, “Try to minimize row and column sizes”.
- Bloom filters: Just like the HFile indexes, those data structures (when enabled) are stored in the LRU.
Currently the recommended way to measure HFile indexes and bloom filters sizes is to look at the region server web UI and checkout the relevant metrics. For keys, sampling can be done by using the HFile command line tool and look for the average key size metric.
It's generally bad to use block caching when the WSS doesn't fit in memory. This is the case when you have for example 40GB available across all your region servers' block caches but you need to process 1TB of data. One of the reasons is that the churn generated by the evictions will trigger more garbage collections unnecessarily. Here are two use cases:
- Fully random reading pattern: This is a case where you almost never access the same row twice within a short amount of time such that the chance of hitting a cached block is close to 0. Setting block caching on such a table is a waste of memory and CPU cycles, more so that it will generate more garbage to pick up by the JVM. For more information on monitoring GC, seeSection 12.2.3, “JVM Garbage Collection Logs”.
- Mapping a table: In a typical MapReduce job that takes a table in input, every row will be read only once so there's no need to put them into the block cache. The Scan object has the option of turning this off via the setCaching method (set it to false). You can still keep block caching turned on on this table if you need fast random read access. An example would be counting the number of rows in a table that serves live traffic, caching every block of that table would create massive churn and would surely evict data that's currently in use.
5. http://hbase.apache.org/book.html#perf.hbase.client.blockcache
11.9.5. Block Cache
Scan instances can be set to use the block cache in the RegionServer via the setCacheBlocks method. For input Scans to MapReduce jobs, this should be false. For frequently accessed rows, it is advisable to use the block cache.
6. https://issues.apache.org/jira/browse/HBASE-4027
Setting -XX:MaxDirectMemorySize in hbase-env.sh enables this feature. The file already has a line you can uncomment and you need to set the size of the direct memory (your total memory - size allocated to memstores - size allocated to the normal block cache - some head room for the other functionalities).
Description
7. http://hbase.apache.org/book.html#trouble.client.oome.directmemory.leak
12.5.6. Client running out of memory though heap size seems to be stable (but the off-heap/direct heap keeps growing)
You are likely running into the issue that is described and worked through in the mail thread HBase, mail # user - Suspected memory leak and continued over in HBase, mail # dev - FeedbackRe: Suspected memory leak. A workaround is passing your client-side JVM a reasonable value for -XX:MaxDirectMemorySize. By default, the MaxDirectMemorySize is equal to your -Xmx max heapsize setting (if -Xmx is set). Try seting it to something smaller (for example, one user had success setting it to 1g when they had a client-side heap of 12g). If you set it too small, it will bring on FullGCs so keep it a bit hefty. You want to make this setting client-side only especially if you are running the new experiemental server-side off-heap cache since this feature depends on being able to use big direct buffers (You may have to keep separate client-side and server-side config dirs).
8. https://issues.apache.org/jira/browse/HBASE-6312
Make BlockCache eviction thresholds configurable
0.95.0에 적용
Release Note:
Description
9. https://issues.apache.org/jira/browse/HBASE-7404
Bucket Cache:A solution about CMS,Heap Fragment and Big Cache on HBASE : 0.95.0에 적용
- Release Note:
Description
10. http://zoomq.qiniudn.com/ZQScrapBook/ZqFLOSS/data/20130319094323/index.html
중국 사람이 작성한 자료라 보기 힘들지만, 영문으로 번역한 내용은 겨우 읽을만함










11. http://www.venturesquare.net/514286
app between에서는 hfile.block.cache.size 값을 0.5로 할당하고 사용하고 있음
12. http://www.marshut.com/kikq/does-hbase-regionserver-benefit-from-os-page-cache.html
관련해서 재미있는 내용
13. hbase의 CacheConfig.java 소스중 일부 -
소스를 통해서 Block Cache 초기화하면서 어떤 설정이 block cache 정책을 결정하는지 알 수 있다.
instantiateBlockCache
/**
* Returns the block cache or <code>null</code> in case none should be used.
*
* @param conf The current configuration.
* @return The block cache or <code>null</code>.
*/
private static synchronized BlockCache instantiateBlockCache(Configuration conf) {
if (globalBlockCache != null) return globalBlockCache;
if (blockCacheDisabled) return null;
float cachePercentage = conf.getFloat(HConstants.HFILE_BLOCK_CACHE_SIZE_KEY,
HConstants.HFILE_BLOCK_CACHE_SIZE_DEFAULT);
if (cachePercentage == 0L) {
blockCacheDisabled = true;
return null;
}
if (cachePercentage > 1.0) {
throw new IllegalArgumentException(HConstants.HFILE_BLOCK_CACHE_SIZE_KEY +
" must be between 0.0 and 1.0, and not > 1.0");
}
// Calculate the amount of heap to give the heap.
MemoryUsage mu = ManagementFactory.getMemoryMXBean().getHeapMemoryUsage();
long lruCacheSize = (long) (mu.getMax() * cachePercentage);
int blockSize = conf.getInt("hbase.offheapcache.minblocksize", HConstants.DEFAULT_BLOCKSIZE);
long offHeapCacheSize =
(long) (conf.getFloat("hbase.offheapcache.percentage", (float) 0) *
DirectMemoryUtils.getDirectMemorySize());
if (offHeapCacheSize <= 0) {
String bucketCacheIOEngineName = conf.get(BUCKET_CACHE_IOENGINE_KEY, null);
float bucketCachePercentage = conf.getFloat(BUCKET_CACHE_SIZE_KEY, 0F);
// A percentage of max heap size or a absolute value with unit megabytes
long bucketCacheSize = (long) (bucketCachePercentage < 1 ? mu.getMax()
* bucketCachePercentage : bucketCachePercentage * 1024 * 1024);
boolean combinedWithLru = conf.getBoolean(BUCKET_CACHE_COMBINED_KEY,
DEFAULT_BUCKET_CACHE_COMBINED);
BucketCache bucketCache = null;
if (bucketCacheIOEngineName != null && bucketCacheSize > 0) {
int writerThreads = conf.getInt(BUCKET_CACHE_WRITER_THREADS_KEY,
DEFAULT_BUCKET_CACHE_WRITER_THREADS);
int writerQueueLen = conf.getInt(BUCKET_CACHE_WRITER_QUEUE_KEY,
DEFAULT_BUCKET_CACHE_WRITER_QUEUE);
String persistentPath = conf.get(BUCKET_CACHE_PERSISTENT_PATH_KEY);
float combinedPercentage = conf.getFloat(
BUCKET_CACHE_COMBINED_PERCENTAGE_KEY,
DEFAULT_BUCKET_CACHE_COMBINED_PERCENTAGE);
if (combinedWithLru) {
lruCacheSize = (long) ((1 - combinedPercentage) * bucketCacheSize);
bucketCacheSize = (long) (combinedPercentage * bucketCacheSize);
}
try {
int ioErrorsTolerationDuration = conf.getInt(
"hbase.bucketcache.ioengine.errors.tolerated.duration",
BucketCache.DEFAULT_ERROR_TOLERATION_DURATION);
bucketCache = new BucketCache(bucketCacheIOEngineName,
bucketCacheSize, writerThreads, writerQueueLen, persistentPath,
ioErrorsTolerationDuration);
} catch (IOException ioex) {
LOG.error("Can't instantiate bucket cache", ioex);
throw new RuntimeException(ioex);
}
}
LOG.info("Allocating LruBlockCache with maximum size " +
StringUtils.humanReadableInt(lruCacheSize));
LruBlockCache lruCache = new LruBlockCache(lruCacheSize, StoreFile.DEFAULT_BLOCKSIZE_SMALL);
lruCache.setVictimCache(bucketCache);
if (bucketCache != null && combinedWithLru) {
globalBlockCache = new CombinedBlockCache(lruCache, bucketCache);
} else {
globalBlockCache = lruCache;
}
} else {
globalBlockCache = new DoubleBlockCache(lruCacheSize, offHeapCacheSize,
StoreFile.DEFAULT_BLOCKSIZE_SMALL, blockSize, conf);
}
return globalBlockCache;
}
}
14. hbase 설정
hbase configuration 페이지는 참조할 수 없지만, 소스상에 있는 설정값을 통해 적절한 값을 유지할 수 있도록 설정이 존재
* LruBlockCache
hbase.lru.blockcache. min.factor
hbase.lru.blockcache.acceptable.factor
* SlabCache
hbase.offheapcache.slab.proportions
hbase.offheapcache.slab.sizes
* BucketCache
hbase.bucketcache.ioengine
hbase.bucketcache.size
hbase.bucketcache.persistent.path
hbase.bucketcache.combinedcache.enabled
hbase.bucketcache.percentage.in.combinedcache
hbase.bucketcache.writer.threads
hbase.bucketcache.writer.queuelength
* Off heap cache : heap 영역관련 설정 변수
hbase.offheapcache.minblocksize
hbase.offheapcache.percentage
* compressed
hbase.rs.blockcache.cachedatacompressed : Configuration key to cache data blocks in compressed format.
hbase.rs.evictblocksonclose : Configuration key to evict all blocks of a given file from the block cache when the file is closed.
15. DirectMemory
http://coders.talend.com/sites/default/files/heapoff-wtf_OlivierLamy.pdf
32public class DirectMemoryUtils {
Returns:
the setting of -XX:MaxDirectMemorySize as a long. Returns 0 if -XX:MaxDirectMemorySize is not set.
36
37
38 public static long getDirectMemorySize() {
39 RuntimeMXBean RuntimemxBean = ManagementFactory.getRuntimeMXBean();
40 List<String> arguments = RuntimemxBean.getInputArguments();
41 long multiplier = 1; //for the byte case.
42 for (String s : arguments) {
43 if (s.contains("-XX:MaxDirectMemorySize=")) {
44 String memSize = s.toLowerCase()
45 .replace("-xx:maxdirectmemorysize=", "").trim();
46
47 if (memSize.contains("k")) {
48 multiplier = 1024;
49 }
50
51 else if (memSize.contains("m")) {
52 multiplier = 1048576;
53 }
54
55 else if (memSize.contains("g")) {
56 multiplier = 1073741824;
57 }
58 memSize = memSize.replaceAll("[^\\d]", "");
59
60 long retValue = Long.parseLong(memSize);
61 return retValue * multiplier;
62 }
63
64 }
65 return 0;
66 }
DirectByteBuffers are garbage collected by using a phantom reference and a reference queue. Every once a while, the JVM checks the reference queue and cleans the DirectByteBuffers. However, as this doesn't happen immediately after discarding all references to a DirectByteBuffer, it's easy to OutOfMemoryError yourself using DirectByteBuffers. This function explicitly calls the Cleaner method of a DirectByteBuffer.
Parameters:
toBeDestroyed The DirectByteBuffer that will be "cleaned". Utilizes reflection.
79
80 public static void destroyDirectByteBuffer(ByteBuffer toBeDestroyed)
81 throws IllegalArgumentException, IllegalAccessException,
82 InvocationTargetException, SecurityException, NoSuchMethodException {
83
84 Preconditions.checkArgument(toBeDestroyed.isDirect(),
85 "toBeDestroyed isn't direct!");
86
87 Method cleanerMethod = toBeDestroyed.getClass().getMethod("cleaner");
88 cleanerMethod.setAccessible(true);
89 Object cleaner = cleanerMethod.invoke(toBeDestroyed);
90 Method cleanMethod = cleaner.getClass().getMethod("clean");
91 cleanMethod.setAccessible(true);
92 cleanMethod.invoke(cleaner);
93
94 }
95}
15. 관련 소스
src/main/java/org/apache/hadoop/hbase/io/hfile
src/main/java/org/apache/hadoop/hbase/io/hfile/slab/
src/main/java/org/apache/hadoop/hbase/util/DirectMemoryUtils.java
src/main/java/org/apache/hadoop/hbase/regionserver/HRegionServer.java
src/main/java/org/apache/hadoop/hbase/regionserver/StoreFile.java
src/test/java/org/apache/hadoop/hbase/io/hfile/
src/test/java/org/apache/hadoop/hbase/io/hfile/slab/
'nosql' 카테고리의 다른 글
| [hbase] 제한적인 트랙잭션 (0) | 2013.06.20 |
|---|---|
| [hbase] shell에서 major compation 지원 (0) | 2013.06.19 |
| hbase 사용사례 발견 (0) | 2013.06.07 |
| [hbase] MSLAB (MemStore-Local Allocation Buffer) 공부 (1) | 2013.06.05 |
| Apache Sqoop) 기존 RDB 데이터를 Hadoop storage(hbase, hive)으로 저장하기 (1) | 2013.06.03 |



