linked 기술 블로그에 따르면 kafka를 중앙 pub/sub 구조의 큐로 잘 사용해 피드 시스템을 처리하고 있다. 재미있는 것은 avro도 사용하고 있다는 점이다.
https://engineering.linkedin.com/blog/2016/04/kafka-ecosystem-at-linkedin
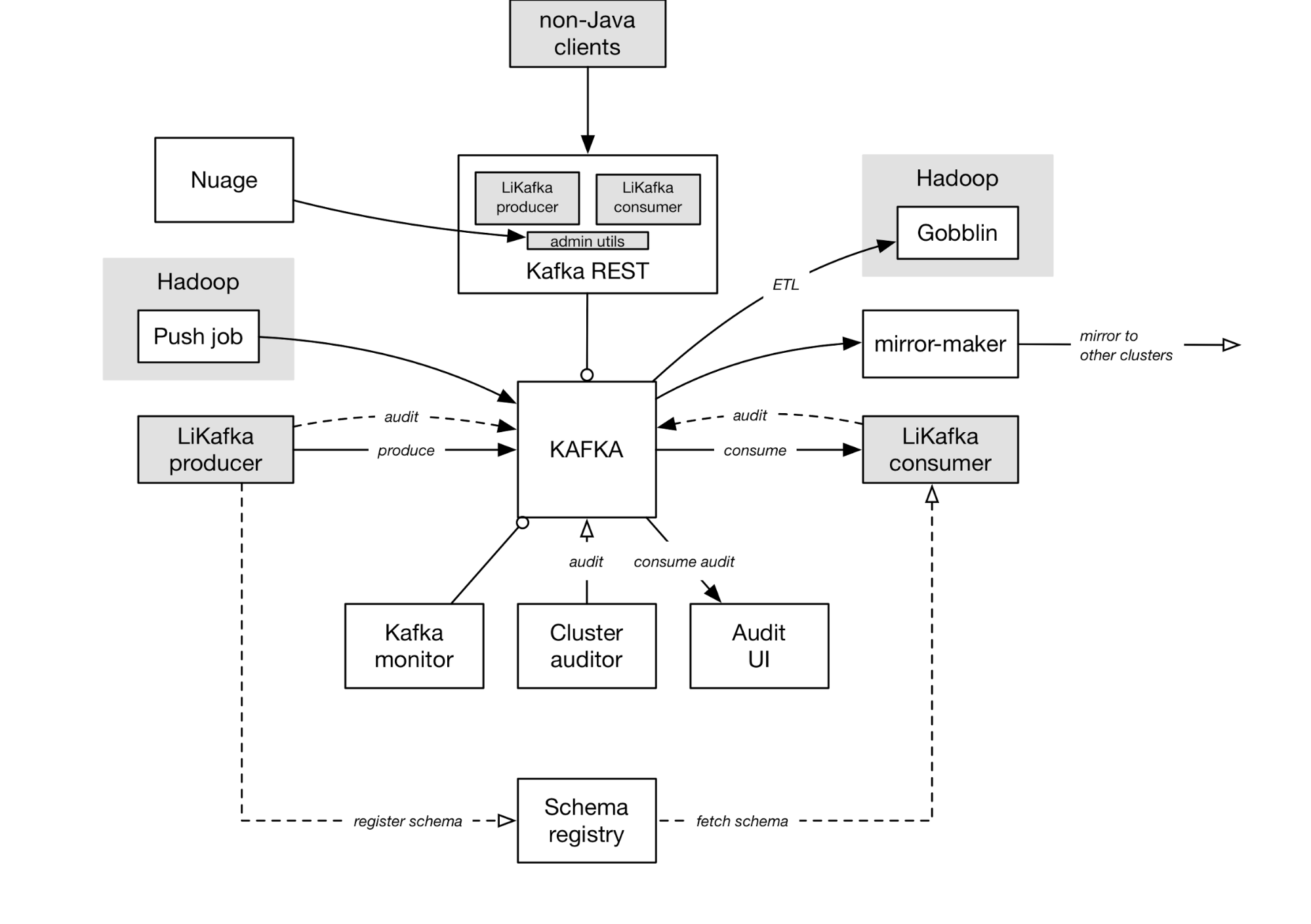
#uber
카프카 데이터 피드를 사용해 분당 수백 번의 승차 정보를 로그 데이터로 저장한 후, 해당 데이터를 Amazon S3에 대량 로드한다. 로컬 데이터 센터의 변경 데이터 로그를 스트리밍한다. json 데이터를 수집한 후 spark-hadoop(paquet)를 사용한다.
https://www.datanami.com/2015/10/05/how-uber-uses-spark-and-hadoop-to-optimize-customer-experience/

하루 50억 세션을 실시간으로 처리하려면 카프카를 스트림 처리 인프라로 사용해야 한다.
https://blog.twitter.com/2015/handling-five-billion-sessions-a-day-in-real-time



# netflix
카프카는 실시간 모니터링 및 이벤트 처리를 위한 넷플릭스의 데이터 파이프 라인의 백본이다.
http://techblog.netflix.com/2013/12/announcing-suro-backbone-of-netflixs.html

# spotify
https://www.meetup.com/ko-KR/stockholm-hug/events/121628932/?eventId=121628932
# yahoo
'kafka' 카테고리의 다른 글
| [kafka] 복제(replication) (0) | 2017.03.17 |
|---|---|
| [kafka] 0.10.1.1 사용하면서 api 사용시 ProducerConfig와 ConsumerConfig를 잘 참조한다 (0) | 2017.03.16 |
| [kafka] kafka 0.10.1.1 - producer / consumer 중요 내용 (0) | 2017.03.08 |
| kafka 0.8과 kafka 0.10 의 Partitioner 변경 내용 (0) | 2017.03.02 |
| [kafka] 0.10.1.1 설치, topic 생성/삭제/수정, 메시지 송신/발신 테스트 (2) | 2017.02.28 |



