J2SE new feature
http://java.sun.com/j2se/1.5.0/docs/relnotes/features.html![]()
Performance Enhancements
- Garbage collection ergonomics
- StringBuilder class
StringBuffer와의 차이점 : 메소드가 Syncronized로 되어 있다. 따라서, 동기화를 목적으로 하지 않는 프로그램에 쓰이는데 용이하지만, 멀티 쓰레드상태에서는 써서는 안된다. 그 때는 StringBuffer를 사용해야 한다. - Java 2DTM technology
- Image I/O
JavaTM Language Features
static import 소스
import static A.Manual.*; public class Test { public static void main(String[] args) { int sum = sum(5); } public static int sum(int... intList) { int sum = 0; return sum; } }
디컴팔된 소스
public class Test { public Test() { } public static void main(String args[]) { int sum = sum(new int[] { 5 }); } public static transient int sum(int intList[]) { int sum = 0; return sum; } }
vararg 소스
import static A.Manual.*; public class Test { public static void main(String[] args) { int sum = sum(5); } public static int sum(int... intList) { int sum = 0; return sum; } }
디컴팔된 소스
public class Test { public Test() { } public static void main(String args[]) { int sum = sum(new int[] { 5 }); } public static transient int sum(int intList[]) { int sum = 0; return sum; } }
enum
public class Test { enum STATE {INIT, PAUSED, STARTED, ENDED}; }
디컴팔된 소스
public class Test { static final class STATE extends Enum { public static STATE[] values() { STATE astate[]; int i; STATE astate1[]; System.arraycopy(astate = ENUM$VALUES, 0, astate1 = new STATE[i = astate.length], 0, i); return astate1; } public static STATE valueOf(String s) { return (STATE)Enum.valueOf(Test$STATE, s); } public static final STATE INIT; public static final STATE PAUSED; public static final STATE STARTED; public static final STATE ENDED; private static final STATE ENUM$VALUES[]; static { INIT = new STATE("INIT", 0); PAUSED = new STATE("PAUSED", 1); STARTED = new STATE("STARTED", 2); ENDED = new STATE("ENDED", 3); ENUM$VALUES = (new STATE[] { INIT, PAUSED, STARTED, ENDED }); } private STATE(String s, int i) { super(s, i); } } public Test() { } }
autoboxing/unboxing
import java.util.ArrayList; import java.util.List; public class Test { public static void main(String[] args) { List<Integer> list = new ArrayList<Integer>(); list.add(1); } }
디컴팔된 소스
import java.util.ArrayList; import java.util.List; public class Test { public Test() { } public static void main(String args[]) { List list = new ArrayList(); list.add(Integer.valueOf(1)); } }
Generic
import java.util.ArrayList; import java.util.List; import A.Manual; public class Test { public static void main(String[] args) { List<Manual> list = new ArrayList<Manual>(); list.add(new Manual()); } }
package A; public class Manual { private int operation; //setter, getter }
디컴팔된 소스
import A.Manual; import java.util.ArrayList; import java.util.List; public class Test { public Test() { } public static void main(String args[]) { List list = new ArrayList(); list.add(new Manual()); } }
'java core' 카테고리의 다른 글
| jconsole 사용하기 (0) | 2007.10.01 |
|---|---|
| jconsole (0) | 2007.09.28 |
| ZipInputStream으로 압축시 한글 디렉토리가 안에 있을때.. (0) | 2007.09.04 |
| [윈도우즈 용] 스레드 덤프 채취하는 툴 (0) | 2007.08.21 |
| 메모리 덤프 (0) | 2007.08.21 |
요즘 원자재 가격이 급하락 하고 있다고 한다.
가격정보 볼라니.. 돈내라고 한다. 그래서, 관련 정보를 얻어보았다..
무료
http://ifc.yahoo.co.kr/html/ITEM02_2.html
http://finance.yahoo.com/futures
유료
http://www.koreapds.com/commodity/kp_main/main.php
'Economics' 카테고리의 다른 글
| 월간 KRX Magazine (0) | 2008.04.05 |
|---|---|
| 시중유동성의 정확한 의미 (0) | 2008.03.20 |
| <img src="http://blogimgs.naver.com/nblog/ico_scrap01.gif" class="i_scrap" width="50" height="15" alt="본문스크랩" /> 주가와 경기 / 경기선행지수, 동행지수, 후행지수 (0) | 2006.07.27 |
| 전자공시 회사 (0) | 2006.05.17 |
| 자본금의 종류와 뜻에대하여 (0) | 2006.05.13 |
우리는 기본적으로 사람들앞에서 무엇인가를 발표를 해야 할때, 어떤 생각을 가져야 할까..
직장상사는 이런 식의 발표자를 좋아할 것이다.
타겟을 정확히 분석하고 분명한 내용을 발표하는 것이 중요한데..
실제로는 그러지 못하다는 것...
명확한 예를 적어본다.
1. 혼자만 알고 있는 것을 남들도 다 안다고 생각하지 말기 (타겟 분석)
2. 필요없는 정보를 나열함으로서 듣는 이의 시간을 소비하지 않는다. (타겟 분석)
3. 인과(원인-결과)관계와 상관(relation) 관계를 명확하게 한다. (분명한 내용)
4. 단위를 빼먹지 않고, 분석의 단위를 정확하게 (분명한 내용)
5. 정확한 문제 정의 (분명한 내용)
'프레젠테이션' 카테고리의 다른 글
| 프레젠테이션 달인이 된 최대리에서. (0) | 2008.04.27 |
|---|---|
| 나만의 차별적인 프레젠테이션 기법 (0) | 2008.02.24 |
| 맥월드에서 스티브 잡스의 키노트 (0) | 2007.06.04 |
| 스티브 잡스와 다른 게시트 발표자와의 프레젠테이션 스타일 비교 (0) | 2007.06.04 |
| 스티브 잡스가 연설한 스탠퍼드 대학의 졸업식 연사 글 (0) | 2007.06.04 |
jakarta-taglibs-src-20060829 소스를 다운받는다.
custom tag 라이브러를 사용했는데, memberid를 사용했다.
|
<hb:usercontribinfo memberId="${param.memberid}" /> |
실제 자바 클래스이다.
|
public class UserContribListTag extends TagSupport { public int doStartTag() throws JspException { memberId = (String) ExpressionEvaluatorManager.evaluate("memberId", memberId, String.class, this, pageContext); |
|
<ExpressionEvaluatorManager.java> public static Object evaluate(String attributeName, String expression, Class expectedType, Tag tag, PageContext pageContext) throws JspException { // the evaluator we'll use ExpressionEvaluator target = getEvaluatorByName(EVALUATOR_CLASS); // 이 부분은 문제 없음 // delegate the call return (target.evaluate(attributeName, expression, expectedType, tag, pageContext)); } |
ExpressionEvaluator target = getEvaluatorByName(EVALUATOR_CLASS);
이 부분은 Target 인스턴스(ExpressionEvaluator)은 Evaluator 라는 클래스를 생성한다. Evaluator 는 내부적으로 static ELEvaluator 객체를 리턴하고, ELEvaluator의 Wrapper 클래스인데..
(target.evaluate(attributeName, expression, expectedType, tag, pageContext));
이때 ELEvalueator의 evaluator 메소드를 호출하게 된다. 다음의 코드를 죽 따라가보면 알겠지만, attributeName 파라미터로 넘겨지는 pExpressionString 아큐먼트를 쫓아가다 보면, sCachedExpressionStrings Map에 추가되는 것이 보인다.
바로 여기서도 static map이 있었다. 그래서, memberid가 계속 추가될 때마다 문제가 된 부분이었다.
|
<ELEvaluator.java> static Map sCachedExpressionStrings = Collections.synchronizedMap (new HashMap ()); public Object evaluate (String pExpressionString, Object pContext, Class pExpectedType, Map functions, String defaultPrefix) throws ELException { return evaluate (pExpressionString, pContext, pExpectedType, functions, defaultPrefix, sLogger); } Object evaluate (String pExpressionString, Object pContext, Class pExpectedType, Map functions, String defaultPrefix, Logger pLogger) throws ELException { // Check for null expression strings if (pExpressionString == null) { throw new ELException (Constants.NULL_EXPRESSION_STRING); } // Get the parsed version of the expression string Object parsedValue = parseExpressionString (pExpressionString); // Evaluate differently based on the parsed type if (parsedValue instanceof String) { // Convert the String, and cache the conversion String strValue = (String) parsedValue; return convertStaticValueToExpectedType (strValue, pExpectedType, pLogger); } else if (parsedValue instanceof Expression) { // Evaluate the expression and convert Object value = ((Expression) parsedValue).evaluate (pContext, mResolver, functions, defaultPrefix, pLogger); return convertToExpectedType (value, pExpectedType, pLogger); } else if (parsedValue instanceof ExpressionString) { // Evaluate the expression/string list and convert String strValue = ((ExpressionString) parsedValue).evaluate (pContext, mResolver, functions, defaultPrefix, pLogger); return convertToExpectedType (strValue, pExpectedType, pLogger); } else { // This should never be reached return null; } } public Object parseExpressionString (String pExpressionString) throws ELException { // See if it's an empty String if (pExpressionString.length () == 0) { return ""; } // See if it's in the cache Object ret = mBypassCache ? null : sCachedExpressionStrings.get (pExpressionString); if (ret == null) { // Parse the expression Reader r = new StringReader (pExpressionString); ELParser parser = new ELParser (r); try { ret = parser.ExpressionString (); sCachedExpressionStrings.put (pExpressionString, ret); } catch (ParseException exc) { throw new ELException (formatParseException (pExpressionString, exc)); } catch (TokenMgrError exc) { throw new ELException (exc.getMessage ()); } } return ret; } |
메모리가 계속 늘 나는 현상을 발견했는데.. 정확하게 문제를 파악하지 못한것이 흠이었다.
현상은 다음과 같다.


'web' 카테고리의 다른 글
| 외부싸이트에서 호출되는 것 확인하기 (0) | 2007.09.22 |
|---|---|
| HTTPClient을 이용한 로그인 테스트 (0) | 2007.09.19 |
| java.net.NoRouteToHostException: No route to host 해결 (0) | 2007.09.04 |
| 웹스나이퍼 (0) | 2007.09.04 |
| <img src="http://blogimgs.naver.com/nblog/ico_scrap01.gif" class="i_scrap" width="50" height="15" alt="본문스크랩" /> 다국어 인코딩 문제의 위치 및 까발리기 (0) | 2007.09.04 |
모니터링 툴이다.
mytop - a top clone for MySQL
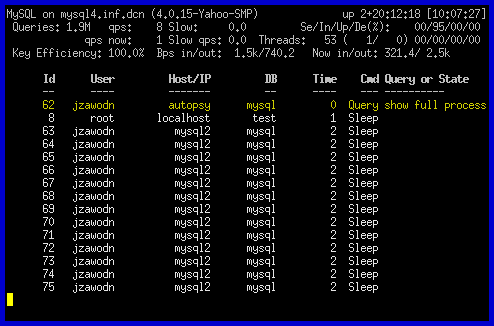
설치
1. DBI Install
# tar xvzf DBI.tar.gz
# cd DBI
# perl Makefile.PL
# make
# make install
2. DBD-Mysql Install
# tar xvzf DBD-Mysql.tar.gz
# cd DBD-Mysql
# perl Makefile.PL
# make
# make install
3. Term::ReadKey Install
# tar xvzf TermReadKey.tar.gz
# cd TermReadKey
# perl Makefile.PL
# make
# make install
4. mytop Install
# tar xvzf mytop.tar.gz
# cd mytop
# perl Makefile.PL
# make
# make install
-------------------------------------
홈디렉터리에 다음 파일을 만든다.
# vi .mytop
user=root
pass=password
host=localhost
db=cast
또는
user=root
pass=
host=localhost
db=test
delay=5
port=3306
socket=
batchmode=0
header=1
color=1
idle=1
이렇게 사용가능하다.
http://jeremy.zawodny.com/mysql/mytop/mytop.html
설명을 보니, ansi color를 이용해서 색깔도 낼 수 있다.
<옵션 설명>
d - 특정 디비에 대해서만 보는 경우
f - 지정된 쓰레드가 실행중인 쿼리를 모두 출력
h - 간단히 보기
i - 쉬고있는 쓰레드는 리스트에서 제외
k - 쓰레드 연결을 종료
m - 초당 실행 쿼리수 보기
p - 화면 정지
q - mytop 종료
r - FLUSH STATUS 실행
s - 화면 갱신 시간 설정
u - 특정 사용자의 쓰레드만 보기
출처 :
mytop : http://jeremy.zawodny.com/mysql/mytop/
펄 모듈 : http://search.cpan.org/
'DB' 카테고리의 다른 글
| <img src="http://blogimgs.naver.com/nblog/ico_scrap01.gif" class="i_scrap" width="50" height="15" alt="본문스크랩" /> [강좌] 프레임?p없이 "IBatis 처음 사용하기" 슈퍼 초.. (0) | 2007.09.23 |
|---|---|
| ORA-01013 에러 (0) | 2007.09.23 |
| mysql 모니터링하기 (0) | 2007.09.12 |
| mysqladmin 활용 (0) | 2007.09.12 |
| mysql 튜닝 관련 (0) | 2007.09.12 |
watch를 이용하면 mysql 모니터링이 가능하다.
프로세스 리스트를 보기
watch -n1 "mysqladmin -uroot -pansq processlist"
lock된 프로세스의 갯수를 구하기
watch -n1 "mysqladmin -uroot -pansqo processlist | grep -i 'lock' | wc -l"
lock된 프로세스 보기
watch -n1 "mysqladmin -uroot -pansq processlist"
lock된 프로세스의 갯수를 구하기
watch -n1 "mysqladmin -uroot -pansq processlist | grep -i 'sleep' | wc -l"
매초마다. 특정 쿼리에 해당되는 부분만 화면에 보여준다.
watch -n1 "mysql -uroot -pansq 'cat /etc/psa/.psa.shadow' trade_engine –execute "SELECT NOW(),date_quote FROM sampleData WHERE 1=1 AND permission = '755' AND symbol='IBZL' GROUP BY date_quote;" "
status 정보 보기
watch -n1 "mysqladmin -uroot -pansq status"
Uptime: 281302 Threads: 1 Questions: 27330 Slow queries: 0 Opens: 1771
Flush tables: 1 Open tables: 64 Queries per second avg: 0.097
내용 설명
Uptime : the MySQL server 시작된 후 현재까지 시간 (초)
Threads : 현재 디비서버에 연결된 유저수
Questions : 서버시작후 지금까지 요청된 쿼리수
Slow queries : --log-slow-queries[=file_name] option로 시작된 서버가 variables에 지정된
long_query_time seconds시간보다 큰 쿼리시간을 가진 요청수
Opens : 서버가 시작된 후 현재까지 열렸던 테이블 수
Flush tables : flush ..., refresh, and reload commands된 수
Open tables : 현재 열려 있는 테이블 수
Queries per second avg : 평균 초당 쿼리수
watch -n1 "mysqladmin -uroot -pansq extended-status"
'DB' 카테고리의 다른 글
| ORA-01013 에러 (0) | 2007.09.23 |
|---|---|
| mysql 쿼리 모니터링 mytop (0) | 2007.09.12 |
| mysqladmin 활용 (0) | 2007.09.12 |
| mysql 튜닝 관련 (0) | 2007.09.12 |
| mysql 슬로우 쿼리 확인하기 (0) | 2007.09.12 |
|
mysqladmin 활용방법 총정리
출처
http://mytechnic.com/MT_Community/index.php?mtcode=class&seq=92&mtact=read
▶ 작성자 : 운비(unbinara@dreamwiz.com) |
'DB' 카테고리의 다른 글
| mysql 쿼리 모니터링 mytop (0) | 2007.09.12 |
|---|---|
| mysql 모니터링하기 (0) | 2007.09.12 |
| mysql 튜닝 관련 (0) | 2007.09.12 |
| mysql 슬로우 쿼리 확인하기 (0) | 2007.09.12 |
| mysql MYSQL 슬로우 쿼리 mysql slow query 보기 (0) | 2007.09.12 |
오늘 mysql때문에 고생해서 그런지.. 자료를 모으고 있다.
출처
http://www.leopit.com/Leophp/board/lecture_board/view.php?id=42&board_mode=mysql
---------------------------
mysql의 최대 성능 향상 방법
출처 : tunelinux.co.kr
---------------------------
10.1 버퍼 크기 조정
mysqld 서버가 사용하는 기본 버퍼 크기는 다음의 명령으로 알 수 있다.
shell> mysqld --help
이 명령은 모든 mysqld 옵션의 목록과 설정 변수를 보여준다. 출력되는 내용은 기본값을
포함하고 있으며 다음과 비슷하다.
Possible variables for option --set-variable (-O) are:
back_log current value: 5
connect_timeout current value: 5
join_buffer current value: 131072
key_buffer current value: 1048540
long_query_time current value: 10
max_allowed_packet current value: 1048576
max_connections current value: 90
max_connect_errors current value: 10
max_join_size current value: 4294967295
max_sort_length current value: 1024
net_buffer_length current value: 16384
record_buffer current value: 131072
sort_buffer current value: 2097116
table_cache current value: 64
tmp_table_size current value: 1048576
thread_stack current value: 131072
wait_timeout current value: 28800
mysqld 서버가 현재 가동중이면 다음의 명령을 통해 실제 변수값을 볼 수 있다.
shell> mysqladmin variables
각 옵션은 밑에서 설명한다. 버퍼 크기, 길이, 스택 크기는 바이트이다. 'K'(킬로바이트)
나 'M'(메가바이트)를 앞에 붙여 값을 지정할 수 있다. 예를 들면 16M는 16 메가바이트를
가리킨다. 대소문자는 구별하지 않는다. 16M 와 16m은 같다.
-back_log
mysql이 가질 수 있는 최대 연결 요청의 수. 이것은 main mysql 스레드가 매우 짧은 시간
동안 매우 많은 연결 요청을 받을 때 기능을 한다. 이때 메인 스레드가 연결을 체크하고 새
로운 스레드를 시작하는데는 약간의 시간이 걸린다.(그러나 아주 짧은 시간임) back_log 값
은 mysql이 순간적으로 새로운 요청에 답하는 것을 멈추기전에 이 짧은 시간동안 얼마나
많은 요청을 쌓아두고 있는지를 지정한다. 매우 짧은 시간동안 매우 많은 연결이 예상될때
만 이 값을 증가시켜야 한다.
다른 말로 이 값은 tcp/ip 연결을 받는 listen queue의 크기이다. 각 운영체제마다 이러한 큐
의 크기에 한계가 있다. Unix system call listen(2) 매뉴얼페이지에 자세한 정보가 있다. ba
ck_log값의 한계는 운영체제 문서를 확인해봐라. back_log를 최대값보다 더 높여도 효과가
없다.
-connect_timeout
Bad handshake에 반응하기 전에 연결 패킷을 mysql 서버에서 기다리는 시간.(초)
-join_buffer
(인덱스를 사용하지 않는 조인의) full-join에서 사용하는 버퍼의 크기. 버퍼는 두 테이블 사
이에서 각 full-join마다 한번 할당이 된다. 인덱싱을 추가하지 못할 때 조인 버퍼를 증가시
키면 full join의 속도를 향상시킬 수 있다. (일반적으로 빠르게 조인을 하는 가장 좋은 방법
은인덱스를 추가하는 것이다)
-key_buffer
인덱스 블락은 버퍼링되고 모든 스레드에서 공유한다. 키 버퍼는 인덱스 블락에서 사용하는
버퍼의 크기이다. 인덱스가 많은 테이블에서 delete나 insert 작업을 많이 하면 키 버퍼값을
증가시키는 것이 좋다. 더 빠른 속도를 내려면 LOCK TABLES를 사용하자. [Lock Tables]
참고.
-max_allowed_packet
한 패킷의 최대 크기. 메시지 버퍼는 net_buffer_length 바이트로 초기화되지만 필요하면 최
대 허용 패킷 바이트를 증가시킬 수 있다.기본값은 큰 패킷을 잡기에는 작다. 거대 BLOB
컬럼을 사용한다면 값을 증가시켜야 한다. 사용자가 원하는 최대 blob만큼 크게 해야 한다.
-max_connections
동시 클라이언트 숫자. mysqld가 필요로하는 파일 지시자(descriptor)의 숫자만큼 값을 늘려
야 한다. 밑에서 파일 디스크립터 제한에 대한 내용을 참고하자.
-max_connect_errors
호스트에서 최대 연결 에러이상의 interrupted 연결이 있으면 더 많은 연결을 위해 호스트는
block화된다. FLUSH HOSTS 명령으로 호스트의 block을 해제할 수 있다.
-max_join_size
최대 조인 크기이상으로 레크도를 읽는 조인을 하면 에러가 난다. 만약 사용자가 where 문
을 사용하지 않고 시간이 많이 걸리면서 몇백만개의 레코드를 읽는 조인을 수행하려 하면
이 값을 설정한다.
-max_sort_length
BLOB나 TEXT 값으로 정열할때 사용하는 바이트의 숫자. (각 값중 오직 첫번째 max_sort
_length 바이트만 사용된다. 나머지는 무시된다)
-net_buffer_length
질의에서 통신 버퍼가 초기화되는 크기. 일반적으로 바뀌지 않지만 매우 적은 메모리를 가
지고 있을 때 예상되는 질의에 맞게 세팅할 수 있다. (이것은 클라이언트에 가는 예상된 sql
문의 길이이다. 질의문이 이 크기를 넘으면 버퍼는 자동으로 max_allowed_packet 바이트까
지 증가한다)
-record_buffer
순차적인 검색을 하는 각 스레드에서 각 검색 테이블에 할당하는 버퍼 크기. 순차적인 검색
을 많이 하면 이 값을 증가시켜야 한다.
-sort_buffer
정렬이 필요한 각 스레드에서 할당하는 버퍼 크기. order by 나 group by 오퍼레이션을 빠
르게 하려면 이 값을 증가시킨다. 16.4 [임시 파일] 참고.
-table_cache
모든 스레드에서 열 수 있는 테이블의 숫자. mysqld가 필요로 하는 파일 디스크립터의 숫
자만큼 이 값을 증가시켜라. mysql은 각 유일한 오픈 테이블에서 두개의 파일 디스크립터가
필요하다. 파일 디스크립터 제한을 참고한다. 테이블 캐쉬가 어떻게 작동하는지는 10.6 [테
이블 캐쉬]를 참고한다.
-tmp_table_size
임시 테이블이 이 값을 넘으면 mysql은 "The Table tbl_name is full"이라는 에러 메시지를
낸다. 매우 많은 group by 질의를 사용하면 이 값을 증가시켜야 한다.
-thread_stack
각 스레드의 스택 사이즈. creash-me test(**역자주 : 데이터베이스의 벤치마킹을 하는 테스
트입니다. 말그대로 데이터베이스를 죽여주지요) 에서 잡히는 많은 제한은 이 값에 달려있
다. 기본값은 일반적으로 충분히 크다. 11장의 [벤치마크] 참조
-wait_timeout
연결을 끊기전에 연결 활동(activity)을 서버에서 기다리는 시간(초).
table_cache 와 max_connections는 서버가 열 수 있는 최대 파일 갯수에 영향을 미친다. 이
값을 증가시키면 운영시스템에서 오픈 파일 디스크립터의 per-process 숫자의 한계까지 올
릴 수 있다. (** ... imposed by your operating system on the per-process number of
open file descriptors. 번역이 이상하므로 영문 참고)
그러나 많은 시스템에서 이 한계를 증가시킬수 있다. 이렇게 하려면 각 시스템에서 이 한계
를 변화시키는 방법이 매우 다양하므로 운영체제 문서를 참고해야 한다.
table_cache 는 max_connections 와 관계가 있다. 예를 들면 200개의 연결이 있으면 최소 2
00 * n 의 테이블 캐쉬를 가져야 한다. 여기서 n은 조인에서 테이블의 최대 숫자이다.
mysql은 매우 유용한 알고리즘을 사용하기 때문에 일반적으로는 매우 적은 메모리로 사용
할 수 있으며 메모리가 많을 수록 성능이 더 많이 향상된다.
많은 메모리와 많은 테이블을 가졌고 중간정도 숫자의클라이언트에서 최대의 성능을 원한다
면 다음과 같이 사용한다.
shell> safe_mysqld -O key_buffer=16M -O table_cache=128
-O sort_buffer=4M -O record_buffer=1M &
메모리가 적고 연결이 많으면 다음과 같이 사용한다.
shell> safe_mysqld -O key_buffer=512k -O sort_buffer=100k
-O record_buffer=100k &
또는:
shell> safe_mysqld -O key_buffer=512k -O sort_buffer=16k
-O table_cache=32 -O record_buffer=8k -O net_buffer=1K &
매우 많은 연결이 있을 때 mysqld가 각 연결마다 최소한의 메모리를 사용하도록 설정하지
않았다면 "swapping problems" 문제가 생길 것이다.
mysqld에서 옵션을 바꾸었으면 그것은 서버의 해당하는 인스턴스에만 영향을 미친다는 것
을 기억하자.
옵션을 바꾸었을때의 효과를 보기 위해 다음과 같이 해보자.
shell> mysqld -O key_buffer=32m --help
마지막에 --help 옵션이 들어간 것을 기억하자. 그렇지 않으면 커맨드 라인에서 사용한 옵
션의 효력은 출력에는 반영되지 않을 것이다.
10.2 메모리 사용 방법 <메모리 최적화>
아래에서 설명하는 목록은 mysqld 서버가 메모리를 사용하는 방법에 대해서 나타내고 있
다. 메모리 사용과 관련된 서버의 변수 이름이 주어진다.
- 키 버퍼(변수 key_buffer)는 모든 스레드에서 공유한다. 서버에서 사용하는 다른 버퍼는
필요한대로 할당이 된다.
- 각 연결은 각 스레드마다의 특정한 공간을 사용한다. 스택(64k, 변수 thread_stack) , 연결
버퍼(변수 net_buffer_length), result 버퍼 (변수 net_buffer_length) 등. 연결 버퍼와 result
버퍼는 필요할때 max_allowed_packet 까지 동적으로 증가된다. 질의가 수행될 때 현재의
질의문의 복사문이 또한 할당이 된다.
(** When a query is running a copy of the current query string is also alloced.)
- 모든 스레드는 같은 기본 메모리를 공유한다.
- 메모리 맵은 아직 지원이 안된다. (압축 테이블을 제외하고. 그러나 이것은 다른 이야기이
다) 왜냐하면 4GB의 32비트 메모리 공간은 대부분의 대형 테이블에서 충분히 크기가 않기
때문이다. 우리가 64비트 주소 공간을 가진 시스템을 가지게 될 때 우리는 메모리 맵핑을
위한 일반적인 지원을 추가할 것이다.
- 테이블에서 순차적인 검색을 하는 각 요청은 read 버퍼에 할당이 된다. (변수 record_buff
er)
- 모든 조인은 한번에 수행이 되며 대부분의 조인은 임시 테이블을 생성하지 않고 수행이
된다. 대부분의 테이블은 메모리 기반(HEAP) 테이블이다. 거대 길이의 레코드를 가졌거나
BLOB 컬럼을 포함한 임시 테이블은 디스크에 저장이 된다. 현재의 문제는 메모리 기반 테
이블이 tmp_table_size를 초과했을때 "The table tbl_name is full"이라는 에러가 생기는 것
이다. 가까운 시일안에 필요할때 자동적으로 메모리 기반(HEAP) 테이블을 디스크 기반(NI
SAM) 테이블로 바꾸도록 고칠 것이다.
이 문제를 해결하기 위해서 mysqld의 tmp_table_size 옵션을 설정하여 임시 테이블 크기를
늘이거나 클라이언트 프로그램에서 SQL_BIG_TABLES라는 sql 옵션을 설정하여야 한다. 7.
24 SET OPTION 을 참고하자.
mysql 3.20에서 임시 테이블의 최대 크기는 record_buffer*16이다. 3.20 버전을 사용하고 있
다면 record_buffer의 값을 증가시켜야 한다. 또한 mysqld를 시작할 때 --big-tables 옵션을
사용하여 항상 임시 테이블을 디스크에 저장할 수 있지만 질의 속도에 영향을 미친다.
- 정열을 하는 대부분의 요청은 정렬 버퍼와 하나나 두개의 임시 파일을 할당한다. 16.4의
[임시 파일]을 참고한다.
- 대부분의 파징(parsing)과 계산은 지역 메모리에서 이루어진다. 작은 아이템에는 메모리 o
verhead가 필요없고 일반적인 느린 메모리 할당(slow memory allocation)과 freeing(메모리
해제)는 무시된다. 메모리는 오직 예상지 못한 거대 문자열에서 할당이 된다.( mallloc() 과
free() 사용)
- 각 인덱스 파일은 한번에 열리며 각 병행수행되는 스레드에서 데이터 파일은 한번에 열
린다. 각 병행수행 스레드마다 테이블 구조, 각 컬럼의 컬럼 구조, 3 * n 의 버퍼 크기가 할
당된다. ( n은 최대 레코드 길이이며 BLOB 컬럼은 해당하지 않는다) BLOB는 BLOB 데이
터의 길이에 5에서 8 바이트를 더한 값을 사용한다.
- BLOB 컬럼을 가진 각 테이블에서 버퍼는 거대 BLOB 값을 읽을 수 있도록 동적으로 커
진다. 테이블을 검색하면 버퍼는 최대 BLOB의 값만큼 버퍼가 할당이 된다.
- 모든 사용중인 테이블의 테이블 핸들러는 캐쉬에 저장되며 FIFO로 관리가 된다. 일반적
으로 캐쉬는 64 엔트리를 갖는다. 동시에 두개의 실행 스레드에서 테이블을 사용하면 캐쉬
는 테이블의 두 엔트리를 포함한다. 10.6 [테이블 캐쉬]를 참고한다.
- mysqladmin flush-tables 명령은 사용하지 않는 모든 테이블을 닫고 현재 실행되는 스레
드가 끝날 때 모든 사용중인 테이블을 닫는다고 표시한다. 이것은 효과적으로 사용중인 메
모리를 해제한다.
ps 와 다른 시스템 상황 프로그램은 mysqld가 많은 메모리를 사용하고 있다고 보고할 것이
다. 이것은 다른 메모리 주소의 스레드-스택때문에 생긴다. 예를 들면 솔라리스의 ps 는 스
택사이의 사용하지 않는 메모리를 사용하는 메모리로 간주한다. 이것은 swap -s를 이용 사
용가능한 스왑을 체크하여 확인할수 있다. 우리는 mysqld를 상용 메모리 유출 측정 프로그
램으로 테스팅해서 mysqld에는 메모리 유출이 없다.
10.3 속도 향상에 영향을 미치는 컴파일/링크 방법 <컴파일시 최적화하기>
다음 테스트의 대부분은 리눅스와 mysql 벤치마크를 가지고 수행되었지만 다른 운영 시스
템에도 암시해주는 것이 있다.
static으로 링크를 할때 가장 빠른 실행 속도를 얻을 수 있다. 데이터베이스에 연결하기 위
해 TCP/IP보다는 유닉스 소켓을 사용하면 더 좋은 성능을 낼 수 있다.
리눅스에서 pgcc와 -O6을 사용하면 가장 빠르다. 'sql_yacc.cc'를 이 옵션으로 컴파일하려면
gcc/pgcc는 모든 성능을 내기 위해 많은 메모리가 필요하기 때문에 180M의 메모리가 필요
하다. 또한 mysql을 설정할때 libstdc++ 라이브러리를 포함하지 않기 위해 CXX=gcc라고 설
정해야 한다.
- pgcc를 사용하고 모두다 -O6 옵션으로 컴파일하면 mysqld 서버는 gcc로 컴파일한 것보
다 11% 빨라진다.
- 동적으로 링크하면 (-static을 사용하지 않고) 13% 느려진다.
If you connect using TCP/IP rather than Unix sockets, the result is 7.5% slower.
- 유닉스 소켓을 사용하는 것보다 tcp/ip로 연결하는 것이 7.5% 느려진다.
- On a Sun sparcstation 10, gcc 2.7.3 is 13% faster than Sun Pro C++ 4.2.
- On Solaris 2.5.1, MIT-pthreads is 8-12% slower than Solaris native threads.
(** 번역을 안한 이후. 리눅스랑 상관없으니깐... **)
TcX에서 제공한 mysql 리눅스 배포판은 pgcc로 컴파일되었고 정적으로 링크되었다.
10.4 How MySQL uses indexes
prefix- and end-space compressed. See section 7.26 CREATE INDEX syntax (Compatibil
ity function).
모든 인덱스(PRIMARY, UNIQUE and INDEX()) 는 B-trees 에 저장된다. 문자열은 자동적
으로 앞 뒤의 공간(?)이 압축된다. 7.26 [인덱스 생성] 참고.
인덱스의 사용 :
- WHERE 문에서 해당하는 레코드 빨리 찾기
- 조인을 수행할때 다른 테이블에서 레코드 가져오기
- 특정 키에서 MAX() 나 MIN() 값 찾기
- 소팅이나 그룹화할때 인덱스 키를 사용하면 테이블을 정열하거나 그룹화한다. 키에 DES
C가 붙으면 역순으로 인덱스를 읽는다.
- 어떤 경우에는 데이터 파일에 묻지 않고 값을 가져온다. 어떤 테이블에서 사용하는 모든
컬럼이 숫자이고 특정 키로 형성되어있으면 빠른 속도로 인덱스 트리에서 값을 가져올 수
있다.
다음 예제를 보자.
mysql> SELECT * FROM tbl_name WHERE col1=val1 AND col2=val2;
다중 컬럼 인덱스가 col1 과 col2에 있으면 해당하는 레코드를 직접 가져올 수 있다. 분리
된 단일 컬럼 인덱스가 col1 과 col2 에 있으면 최적화기는 어떤 인덱스가 더 적은 레코드
를 가졌는지 확인하고 레코드를 가져오기 위해 그 인덱스를 사용하도록 결정한다.
테이블이 다중 컬럼 인덱스를 가졌다면 최적화기가 레코드를 찾는데 어떤 인덱스키를 사용
할 수 있다. 예를 들면 세가지 컬럼 인덱스(col1, col2, col3)를 가졌다면 (col1), (col1,col2)
(col1,col2,col3) 인덱스를 사용하여 검색을 할 수 있다.
MySQL can't use a partial index if the columns don't form a leftmost prefix of the inde
x.
Suppose you have the SELECT statements shown below:
(** 해석이 잘 안되는데 예제를 보시면 무슨 말인지 알 수 있을 것임**)
mysql> SELECT * FROM tbl_name WHERE col1=val1;
mysql> SELECT * FROM tbl_name WHERE col2=val2;
mysql> SELECT * FROM tbl_name WHERE col2=val2 AND col3=val3;
If an index exists on (col1,col2,col3), only the first query shown above uses the index.
The second and third queries do involve indexed columns, but (col2) and (col2,col3) are
not leftmost prefixes of (col1,col2,col3).
인덱스가 (col1,col2,col3)로 있다면 위의 질의중 오직 첫번째 질의만 인덱스를 사용한다. 두
번째 및 세번째 질의은 인덱스된 컬럼이 포함되어 있지만 (col2) 와 (col2,col3)는 (col1,col2,c
ol3) 인덱스에 해당하지 않는다.
MySQL also uses indexes for LIKE comparisons if the argument to LIKE is a constant
string that doesn't start with a wildcard character. For example, the following SELECT
stat ements use indexes:
mysql은 또한 LIKE의 인수가 와일드카드 문자로 시작하지 않는 상수 문자열일이라면 LIK
E 비교문에서 인덱스를 사용한다. 예를 들어 다음의 SELECT 문은 인덱스를 사용한다.
mysql> select * from tbl_name where key_col LIKE "Patrick%";
mysql> select * from tbl_name where key_col LIKE "Pat%_ck%";
첫번째 문장에서는 "Patrick" <= key_col < "Patricl" 을 가진 레코드만 고려된다. 두번째 문
장에서는 "Pat" <= key_col < "Pau" 을 가진 레코드만 고려된다.
다음의 SELECT 문은 인덱스를 사용하지 않는다:
mysql> select * from tbl_name where key_col LIKE "%Patrick%";
mysql> select * from tbl_name where key_col LIKE other_col;
첫번째 문장에서 LIKE 값은 와일드카드 문자로 시작하고 있다. 두번째 문장에서는 LIKE
값이 상수가 아니다.
10.5 WHERE 문에서 최적화하기
(이번 절은 완전한 내용을 포함하고 있지는 않다. mysql은 많은 최적화방법이 있다.)
In general, when you want to make a slow SELECT ... WHERE faster, the first thing t
o check is whether or not you can add an index. All references between different tables
should usually be done with indexes. You can use the EXPLAIN command to determine
which indexes are used for a SELECT. See section 7.21 EXPLAIN syntax (Get informat
ion about a SELECT).
일반적으로 느린 SELECT ... WHERE 문을 빠르게 하려면 가장 먼저 확인해야 할 것이 인
덱스 추가 문제이다. 다른 테이블사이에서 모든 레퍼런스(references 참조)는 일반적으로 인
덱스에 의해 수행된다. SELECT 문에서 어떤 인덱스를 사용하는지 결정하기 위해 EXPLAI
N 명령을 사용할 수 있다. 7.21 [Explain]을 참고.
mysql에서 수행하는 최적화는 다음과 같다.
- 불필요한 삽입어 제거
((a AND b) AND c OR (((a AND b) AND (c AND d))))
-> (a AND b ANDc) OR (a AND b AND c AND d)
-상수 폴딩(folding)
(a<b AND b=c) AND a=5
-> b>5 AND b=c AND a=5
- 상수 조건 제거(상수 폴딩때문에 필요)
(B>=5 AND B=5) OR (B=6 AND 5=5) OR (B=7 AND 5=6)
-> B=5 OR B=6
- 인덱스에서 사용되는 상수 표현은 한번에 계산된다.
(Constant expressions used by indexes are evaluated only once.)
- WHERE 절이 없는 단일 테이블의 COUNT(*)는 테이블 정보에서 직접 값을 가져온다.
단일 테이블에서 사용된 NOT NULL 표현도 이와 같이 수행된다.
- 유효하지 않은 상수 표현은 미리 제거된다. mysql은 불가능하고 해당하는 레코드가 없는
SELECT 문을 빠르게 감지한다.
- GROUP BY 나 그룹 펑션(COUNT(), MIN() ...)을 사용하지 않으면 HAVING은 WHERE
에 합쳐진다.
(** HAVING 절에서는 인덱스를 사용하지 못함. 그러므로 가능한 HAVING절을 사용하지
않는게 속도면에서 좋다 **)
- 각 서브 조인에서 빠르게 WHERE 문을 계산하고 가능한한 레코드를 제외하도록 간소하
게 WHERE 문이 만들어진다.
- mysql은 일반적으로 최소한의 레코드를 찾기 위해 인덱스를 사용한다. =, >, >=, <, <=,
BETWEEN 그리고 'something%' 처럼 앞이 와일드카드로 시작하지 않는 LIKE 문등을
사용하여 비교를 할 때 인덱스를 사용한다. (** 10.4 절에서 설명하였듯이 like 를 사용할때
와일드카드로 시작하는 like 문을 사용하면 인덱스를 사용하지 않는다. 일정한 단어로만 시
작하는 컬럼에서 자료를 찾을 때 유용할 것이다. **)
- Any index that doesn't span all AND levels in the WHERE clause is not used to opti
mize the query.
다음의 WHERE 문은 인덱스를 사용한다.:
... WHERE index_part1=1 AND index_part2=2
... WHERE index=1 OR A=10 AND index=2 /* index = 1 OR index = 2 */
... WHERE index_part1='hello' AND index_part_3=5
/* optimized like "index_part1='hello'" */
다음의 WHERE 문은 인덱스를 사용하지 않는다.:
... WHERE index_part2=1 AND index_part3=2 /* index_part_1 is not used */
... WHERE index=1 OR A=10 /* No index */
... WHERE index_part1=1 OR index_part2=10 /* No index spans all rows */
- 질의에서 다른 테이블보다 모든 상수 테이블을 먼저 읽는다. 상수 테이블은 다음과 같다.
ㅇ빈 테이블이나 1개의 레코드만 있는 테이블
ㅇWHERE 문에서 UNIQUE 인덱스나 PRIMARY KEY 를 사용하고 모든 인덱스
는 상수 표현으로된 테이블
다음의 테이블은 상수 테이블로 사용된다.
mysql> SELECT * FROM t WHERE primary_key=1;
mysql> SELECT * FROM t1,t2
WHERE t1.primary_key=1 AND t2.primary_key=t1.id;
- 모든 가능성을 시도하여 테이블을 조인하는데 가장 좋은 조인 조합을 찾는다. (ORDER B
Y나 GROUP BY의 모든 컬럼이 동일한 테이블에서 나오면 조인을 할때 이 테이블이 먼저
선택된다)
- ORDER BY 문과 다른 GROUP BY 문이 있을 때, 또는 ORDER BY 나 GROUP BY가
조인 큐의 첫번째 테이블이 아닌 다른 테이블의 컬럼을 포함하고 있으면 임사 테이블을 만
든다.
- 각 테이블 인덱스를 찾고 레코드의 30%미만을 사용하는 (best) 인덱스가 사용된다. 그런
인덱스가 없으면 빠른 테이블 검색이 사용된다.
- 어떤 경우에는 mysql은 데이터 파일을 조회하지 않고 인덱스에서 레코드를 읽을 수 있
다. 인덱스에서 사용한 모든 컬럼이 숫자라면 질의를 처리하는데 단지 인덱스 트리만을 사
용한다.
- 각 레코드가 출력되기 전에 HAVING 절에 맞지 않는 레코드는 건너뛴다.
다음은 매우 빠른 질의의 예이다:
mysql> SELECT COUNT(*) FROM tbl_name;
mysql> SELECT MIN(key_part1),MAX(key_part1) FROM tbl_name;
mysql> SELECT MAX(key_part2) FROM tbl_name
WHERE key_part_1=constant;
mysql> SELECT ... FROM tbl_name
ORDER BY key_part1,key_part2,... LIMIT 10;
mysql> SELECT ... FROM tbl_name
ORDER BY key_part1 DESC,key_part2 DESC,... LIMIT 10;
다음의 커리는 인덱스 트리만을 사용하여 값을 구한다.(인덱스 컬럼은 숫자라고 가정):
mysql> SELECT key_part1,key_part2 FROM tbl_name WHERE key_part1=val;
mysql> SELECT COUNT(*) FROM tbl_name
WHERE key_part1=val1 and key_part2=val2;
mysql> SELECT key_part2 FROM tbl_name GROUP BY key_part1;
다음의 질의는 개별적인 정열을 하지 않고 정열된 순서대로 열을 가져오는 데 인덱스를 사
용한다:
mysql> SELECT ... FROM tbl_name ORDER BY key_part1,key_part2,...
mysql> SELECT ... FROM tbl_name ORDER BY key_part1 DESC,key_part2 DESC,...
10.6 테이블 열고 닫는 방법
open 테이블의 캐쉬는 table_cache의 최대값까지 커질 수 있다. (기본값 64 ; 이 값은 mysql
d에서 -0 table_cache=# 으로 바꿀 수 있다) 캐쉬가 꽉 찼을때, 그리고 다른 스레드가 테이
블을 열려고 할 때, 또는 mysqladmin refresh 나 mysqladmin flush-tables를 사용할때를 제
외하고는 테이블은 결코 닫히지 않는다.
테이블 캐쉬가 꽉 차면 서버는 캐쉬 엔트리를 사용하도록 조절하기 위해 다음의 절차를 사
용한다.
- 가장 먼저 사용했던 순서대로 현재 사용하지 않는 테이블을 닫는다.
- 캐쉬가 꽉 찼고 어떤 테이블도 닫히지 않지만 새로운 테이블을 열어야 한다면 캐쉬가 필
요한 만큼 임시적으로 확장된다.
- 캐쉬가 임시적으로 확장된 상태이고 테이블을 사용할 수 없는 상황으로 가면 테이블을
닫고 캐쉬를 해제한다.
테이블은 각 동시병행적인 접근때마다 열린다. 동일한 테이블에 접근하는 두개의 스레드가
있거나 같은 질의에서 테이블에 두번 접근하면(with AS) 테이블을 두번 열여야 한다는 의
미이다. 테이블의 첫번째 개방은 두개의 파일 디스크립터를 가진다. ; 추가적인 테이블의 개
방은 하나의 파일 디스크립터를 가질 뿐이다. 처음에 개방에 사용하는 추가적은 파일 디스
크립터는 인덱스 파일에 사용된다. ; 이 디스크립터는 모든 스레드에서 공유된다.
10.6.1 데이터베이스에서 많은 수의 테이블을 만들때의 단점
디렉토리에 많은 파일이 있다면 open, close 그리고 create 오퍼레이션은 느려질 것이다. 서
로 다른 많은 테이블에서 SELECT 문을 수행하면 테이블 캐쉬가 꽉 찰 때 약간의 overhea
d가 있을 것이다. 왜냐면 개방된 테이블이 있다면 다른 테이블은 닫혀야 하기 때문이다. 테
이블 캐쉬를 크게 해서 이러한 오우버헤드를 줄일 수 있다.
10.7 많은 테이블을 여는 이유
mysqladmin status 를 실행할 때 다음과 같이 나올 것이다:
Uptime: 426 Running threads: 1 Questions: 11082 Reloads: 1 Open tables: 12
단지 6테이블을 사용했는데 이러한 결과는 당황스러울 것이다.
mysql은 멀티스레드를 사용한다. 그래서 동시에 같은 테이블에서 많은 질의를 할 수 있다.
같은 파일에 대하여 다른 상황을 가지는 두개의 스레드에 대한 문제를 줄이기 위해 테이블
은 각 동시병행적인 스레드마다 독립적으로 개방된다. 이것은 테이타 파일에서 약간의 메모
리와 하나의 추가적인 파일 디스크립터를 사용한다. 모든 스레드에서 인덱스 파일은 공유된
다.
10.8 데이터베이스와 테이블에서 심볼릭 링크 사용
데이터베이스 디렉토리에서 테이블과 데이터베이스를 다른 위치로 옮기고 새로운 위치로 심
볼릭 링크를 사용할 수 있다. 이렇게 하는 것을 원할 경우가 있다. 예를 들면 데이터베이스
를 더 여유공간이 많은 파일시스템으로 옮기는 경우 등.
mysql에서 테이블이 심볼링 링크되었다는 것을 감지하면 심볼링 링크가 가리키는 테이블을
대신 사용할 수 있다. realpath() call 을 지원하는 모든 시스템에서 작동한다. (최소한 리눅
스와 솔라리스는 realpath()를 지원한다) realpath()를 지원하지 않는 시스템에서 동시에 실
제 경로와 심볼릭 링크된 경로에 접근하면 안된다. 이런 경우에는 업데이트 된후에 테이블
이 모순될 수 있다.
mysql은 기본값으로 데이터베이스 링크를 지원하지 않는다. 데이터베이스간에 심볼릭 링크
를 사용하지 않는 작동을 잘 할 것이다. mysql 데이터 디렉토리에 db1 데이터베이스가 있
고 db1을 가리키는 db2 심볼릭 링크를 만들었다고 해보자:
shell> cd /path/to/datadir
shell> ln -s db1 db2
이제 db1에 tbl_a라는 테이블이 있다면 db2에도 tbl_a가 나타날 것이다. 한 스레드가 db1.tbl
_a를 업데이트하고 다른 스레드가 db2.tbl_a를 업데이트하면 문제가 생길 것이다.
정말로 이 기능이 필요하면 , `mysys/mf_format.c'에서 다음의 코드를 수정해야 한다.:
if (!lstat(to,&stat_buff)) /* Check if it's a symbolic link */
if (S_ISLNK(stat_buff.st_mode) && realpath(to,buff))
위 코드를 다음과 같이 수정한다 :
if (realpath(to,buff))
10.9 테이블에 락 거는 방법
mysql의 모든 락은 deadlock-free 이다. 언제나 질의를 시작할때 한번에 모든 필요한 락을
요청하고 언제나 같은 순서대로 테이블에 락을 걸어 관리한다.
WRITE 락을 사용하는 방법은 다음과 같다:
- 테이블에 락이 없으면 그 테이블에 write 락을 건다.
- 이런 경우가 아니라면 write 락 큐에 락을 요청한다.
READ 락을 사용하는 방법은 다음과 같다:
- 테이블에 write 락이 없으면 그 테이블에 read 락을 건다.
- 이런 경우가 아니라면 read 락 큐에 락을 요청한다.
락이 해제되었을 때 락은 write 락 큐의 스레드에서 사용할 수 있으며 그러고 나서 read 락
큐의 스레드에서 사용한다.
테이블에서 업데이트를 많이 하면 SELECT 문은 더 이상 업데이트가 없을 때까지 기다린
다는 것을 의미한다.
이러한 문제를 해결하기 위해 테이블에서 INSERT 와 SELECT 오퍼레이션을 많이 사용하
는 경우에 다음과 같이 하면 된다. 임시 테이블에 레코드를 입력하고 한번에 임시 테이블에
서 실제 테이블로 레코드를 업데이트한다.
다음의 예를 보자:
mysql> LOCK TABLES real_table WRITE, insert_table WRITE;
mysql> insert into real_table select * from insert_table;
mysql> delete from insert_table;
mysql> UNLOCK TABLES;
만약 어떤 경우에 SELECT문에 우선권을 주고 싶다면 INSERT 옵션에서 LOW_PRIORITY
or HIGH_PRIORITY 옵션을 사용할 수 있다. 7.13 [Insert] 참고. (** LOW_PRIORITY를 지
정하면 클라이언트에서 테이블을 읽지 않을 때까지 INSERT 문 수행이 미루어진다. **)
단일 큐를 사용하기 위해 `mysys/thr_lock.c' 의 락킹 코드를 바꿀 수 있다. 이런 경우 writ
e 락과 read 락은 같은 우선권을 가지며 어떤 애플리케이션에서는 유용할 수 있다.
10.10 테이블을 빠르고 작게 배열하는 방법 <** 테이블 최적화 **>
다음은 테이블에서 최대의성능을 내는 방법과 저장 공간을 절약할 수 있는 테크닉이다:
- 가능한한 NOT NULL로 컬럼을 선언한다. 속도가 빨라지며 각 컬럼마다 1 비트를 절약할
수 있다.
- default 값을 가질 때 유리하다. 입력되는 값이 기본값과 다를 때만 확실하게 값이 입력된
다. INSERT 문에서 첫번째 TIMESTAMP 컬럼이나 AUTO-INCREAMENT 컬럼의 값을
입력할 필요가 없다. 18.4.49 [mysql_insert_id()] 참고.
- 가능한한 테이블을 작게 만드려면 더 작은 integer 타입을 사용하자. 예를 들면 MEDIUM
INT 가 보통 INT 보다 좋다.
- 가변 길이 컬럼이 없다면(VARCHAR, TEXT or BLOB columns), 고정 길이 레코드 포
맷이 사용된다. 이 경우 속도는 더 빠르지만 불행히도(흑흑~) 낭비되는 공간이 더 많다. 10.1
4 [Row format] 참고.
- mysql이 질의를 효과적으로 최적화하기 위해 많은 양의 데이터를 입력한후 isamchk --a
nalyze를 실행하자. 이렇게 하면 동일한 값을 가진 줄의 평균 숫자를 가리키는 각 인덱스의
값을 업데이트한다. (물론 unique 인덱스에서는 항상 1이다)
- 인덱스와 인덱스에 따른 데이타를 정열하려면
isamchk --sort-index --sort-records=1 을 사용하자.(if you want to sort on index 1).
인덱스에 따라 정렬된 모든 레코드를 읽기 위해 unique 인덱스를 가졌다면 이렇게 하는 것
이 속도를 빠르게 하는 가장 좋은 방법이다.
- INSERT 문에서 가능한 다중 값 목록을 사용하자. 개별적인 SELECT 문보다 훨씬 빠르
다. 데이타를 테이블에 입력할 때 LOAD DATA INFILE을 사용하자. 많은 INSERT 문을
사용하는 것보다 보통 20배 빠르다. 7.15 [Load] 참고.
많은 인덱스를 가진 테이블에 데이타를 입력할때 다음의 과정을 사용하면 속도를 향상시킬
수 있다.
1. mysql이나 Perl 에서 CREATE TABLE로 테이블을 만든다.
2. mysqladmin flush-tables 실행. (** 열린 테이블을 모두 닫음 **)
3. isamchk --keys-used=0 /path/to/db/tbl_name 사용. 테이블에서 모든 인덱스 사용을 제
거한다.
4. LOAD DATA INFILE 를 이용 테이블에 데이타를 입력.
5. pack_isam을 가지고 있고 테이블을 압축하기 원하면 pack_isam을 실행.
6. isamchk -r -q /path/to/db/tbl_name 를 이용 인덱스를 다시 생성.
7. mysqladmin flush-tables 실행.
- LODA DATA INFILE 과 INSERT 문에서 더 빠른 속도를 내려면 키 버퍼를 증가시킨
다. mysqld나 safe_mysqld에서 -O key_buffer=# 옵션을 사용하면 된다. 예를 들어 16M는
풍부한 램을 가졌다면 훌륭한 값이다.
- 다른 프로그램을 사용하여 데이타를 텍스트 파일로 덤프할때 SELECT ... INTO OUTFIL
E 을 사용하자. 7.15 [LOAD DATA INFILE] 참고.
- 연속으로 다량의 insert와 update를 할 때 LOCK TABLE을 사용하여 테이블에 락을 걸
면 속도를 향상시킬 수 있다. LOAD DATA INFILE 그리고 SELECT ...INTO OUTFILE
는 원자적이기 때문에 LOCK TABLE을 사용하면 안된다. 7.23 [LOCK TABLES/UNLOCK
TABLES] 참고.
테이블이 얼마나 단편화되었는지 점검하려면 '.ISM' 파일에서 isamchk -evi 를 실행한다. 1
3장 [Maintenance] 참고.
10.11 INSERT 문에서 속도에 영향을 미치는 부분 <** insert 최적화 **>
insert 하는 시간은 다음와 같이 구성된다:
Connect: (3)
Sending query to server: (2)
Parsing query: (2)
Inserting record: (1 x size of record)
Inserting indexes: (1 x indexes)
Close: (1)
(숫자)는 비례적인 시간이다. 이것은 테이블을 개방할때 초기의 overhead를 고려하고 있지
는 않다. (매 동시병행적으로 수행되는 질의마다 발생)
The size of the table slows down the insertion of indexes by N log N (B-trees).
테이블의 크기는 N log N(B-trees)에 따라 인덱스의 입력이 느려진다. (**말이 좀 이상. 테
이블이 커짐에 따라 인덱스 생성도 느려진다는 뜻이겠죵 **)
테이블에 락을 걸거나 insert 문에서 다중 값 목록을 사용하여 입력 속도를 빠르게 할 수
있다. 다중 값 목록을 사용하면 단일 insert 보다 5배 정도 속도가 빨라진다.
mysql> LOCK TABLES a WRITE;
mysql> INSERT INTO a VALUES (1,23),(2,34),(4,33);
mysql> INSERT INTO a VALUES (8,26),(6,29);
mysql> UNLOCK TABLES;
주요한 속도 차이는 모든 INSERT 문이 완료되고 난 후에 한번에 인덱스 버퍼가 쓰여기지
때문에 생긴다. 보통 서로 다른 여러 INSERT 문이 있으면 많은 인덱스 버퍼 플러쉬가 있
을 것이다. 모든 줄을 단일 문으로 입력하면 락은 필요없다.
락킹은 또한 다중 연결 테스트의 총 시간을 줄일 수는 있다. 그러나 어떤 스레드에서는 총
대기시간은 증가할 수 있다.(왜냐면 락을 기다리기 때문이다)
예를 들어보자:
thread 1 does 1000 inserts
thread 2, 3, and 4 does 1 insert
thread 5 does 1000 inserts
락을 사용하지 않으면 2, ,3 4는 1과 5 전에 끝마칠 것이다. 락을 사용하면 2,3,4는 아마도 1
이나 5 전에 끝나지 않을 것이다. 그러나 총 시간은 40% 빨라진다.
INSERT, UPDATE, DELETE 오퍼레이션은 mysql에서 매우 빠르다. 그렇기 때문에 줄에서
5개 이상의 insert나 update를 할 때 락을 추가하면 더 좋은 성능을 얻을 수 있다. 줄에 매
우 많은 자료를 입력한다면 다른 스레드에서 테이블에 접근하도록 하기 위해 때때로(각 100
0줄마다) UNLOCK TABLES를 사용하는 LOCK TABLES 실행하면 된다. 이렇게 하면 좋
은 성능을 낼 수 있다. (** 열심히 입력을 하고 중간에 락을 풀었다가 다시 락을 거는 것
반복함**)
물론 LOAD DATA INFILE 이 더 빠르다.
10.12 DELETE 문에서 속도에 영향을 미치는 부분 <** DELETE 문 최적화 **>
레코드를 삭제하는 시간은 정확히 인덱스 숫자에 비례한다. 레코드를 빠르게 지우기 위해
인덱스 캐쉬의 크기를 증가시킬 수 있다. 기본 인덱스 캐쉬는 1M 이다; 빠르게 삭제하기 위
해 증가되어야 한다.(충분한 메모리를 가지고 있다면 16M로 하자)
10.13 mysql에서 최대 속도를 얻는 방법
벤치마킹을 시작하자! mysql 벤치마크 스위트에서 어떤 프로그램을 사용할 수 있다. (일반
적으로 'sql-bench' 디렉토리에 있음) 그리고 입맞에 맞게 수정하자. 이렇게 하면 당신의 문
제를 해결할 수 있는 다른 해결책을 찾을 수 있으며 당신에게 가장 빠른 해결책을 테스트할
수 있다.
- mysqld를 적절한 옵션으로 시작하자. 메모리가 많을수록 속도가 빠르다.
10.1 [MySQL parameters] 참고.
- SELECT 문의 속도를 빠르게 하기 위해 인덱스를 만들자.
10.4 [MySQL indexes] 참고.
- 가능한 효율적으로 컬럼 타입을 최적화하자. 예를 들면 가능한 NOT NULL로 컬럼을 정
의하자. 10.10 [Table efficiency] 참고.
- --skip-locking 옵션은SQL 요청에서 파일 락킹을 없앤다. 속도가 빨라지지만 다음의 과
정을 따라야 한다:
ㅇ isamchk로 테이블을 체크하거나 수리하기 전에 mysqladmin flush-tables 로 모
든 테이블을 플러시해야 한다. (isamchk -d tbl_name은 언제나 허용된다. 왜냐하면 이건 단
순히 테이블의 정보를 보여주기 때문이다)
ㅇ 동시에 뜬 두개의 mysql 서버가 동일한 테이블을 업데이트하려 한다면 동일한
데이터 파일에 두개의 mysql 서버를 띄우면 안된다.
--skip-locking 옵션은 MIT-pthreads로 컴파일할때 기본값이다. 왜냐면 모든 플랫
폼의 MIT-pthreads에서 flock()가 완전하게 지원이 되지 않기 때문이다.
- 업데이트에 문제가 있다면 업데이트를 미루고 나중에 하자. 많은 업데이트를 하는 것이
한번에 하나를 업데이트하는 것보다 더 빠르다.
- FreeBSD 시스템에서 MIT-pthreads에 문제가 있으면 FreeBSD 3.0 이후 버전으로 업데
이트 하는것이 좋다. 이렇게 하면 유닉스 소켓을 사용하는 것이 가능하며(FreBSD에서 유닉
스 소켓이 MIT-pthreads에서 TCP/IP 연결을 사용하는 것보다 빠르다) 그리고 스레드 패키
지가 조정(intergrated?)되어야 한다.
- 테이블이나 컬럼 단계를 체크하는 GRANT는 성능을 떨어뜨린다.
10.14 로우 포맷과 다른 점은 무엇인가? 언제 VARCHAR/CHAR을 사용해야 하는가?
mysql은 실제의 SQL VARCHAR 타입이 없다. 그대신 mysql은 레코드를 저장하고 이것을
VARCHAR로 에뮬레이트하는데 세가지 방법이 있다.
테이블에 VARCHAR, BLOB, TEXT 컬럼이 없으면 고정 row size를 사용한다. 그외에는
동적 row size를 사용한다. CHAR 과 VARCHAR 컬럼은 애플리케이션의 관점에서 동일하
게 취급된다; 둘다 trailing space는 컬럼을 가져올때 제거된다.
isamchk -d 를 이용 테이블에서 사용하는 포맷을 체크할 수 있다.
(-d 는 "테이블 묘사"를 의미)
mysql은 세가지 다른 테이블 포맷을 가지고 있다; 고정길이, 다이나믹, 압축.
고정 길이 테이블
- 기본 포맷. 테이블에 VARCHAR, BLOB, TEXT 컬럼이 없을 때 사용.
- 모든 CHAR, NUMERIC, DECIMAL 컬럼은 컬럼 길이에 space-padded 이다. (** space-
padded를 무엇이라고 번역해야 할지 애매모호해서 **)
- 매우 빠름
- 캐쉬하기 쉽다
- 손상 후 복구가 쉽다. 왜냐면 고정된 위이에 레코드가 위치하기 때문이다.
- 많은 양의 레코드가 지워졌거나 운영 시스템에서 자유 공간을 늘리길 원치 않는다면 (isa
mchk를 이용) 재조직화할 필요없다.
- 보통 다이나믹 테이블보다 많은 디스크 공간을 필요로 한다.
다이나믹 테이블
- 테이블이 VARCHAR, BLOB, TEXT 컬럼을 포함하고 있을 때 사용.
- 모든 문자열 컬럼은 다이나믹하다.(4보다 작은 길이를 가진 문자열 제외)
- 컬럼이 문자열 컬럼에서 비었거나 ('') 숫자형 컬럼에서 0(NULL 값을 가진 컬럼과 동일
한 것이 아니다) 을 나타내는 비트맵이 모든 레코드 앞에 선행된다. 문자열 컬럼에서 trailin
g space를 제거한 후 zero의 길이를 가지거나 숫자형 컬럼이 zero의 값을 가지면 비트 맵으
로 표시되고 디스크에 저장되지 않는다. 비지 않은 문자는 문자내용에 길이 바이트만큼 추
가되어 저장된다.
- 보통 고정 길이 테이블보다 디스크 공간 절약.
- 줄의 길이를 확장하는 정보를 가지고 줄을 업데이트하면 줄은 단편화될 것이다. 이런 경
우 더 좋은 성능을 위해 때때로 isamchk -r 을 실행해야 한다. 통계적으로(?) isamchk -ei
tbl_name을 사용하자.
- 손상후 복구가 어렵다. 왜냐면 레코드가 많은 조각드로 단편화되고 링크(단편)가 없어지
기 때문이다.
- 다이나믹 사이즈 테이블의 예상되는 열 길이 :
3
+ (number of columns + 7) / 8
+ (number of char columns)
+ packed size of numeric columns
+ length of strings
+ (number of NULL columns + 7) / 8
각 링크마다 6 바이트가 더 있다. 다이나믹 레코드는 업데이트로 레코드가 늘어날때마다 링
크된다. 각 새로운 링크는 최소 20바이트일 것이며, 그래서 다음의 확장은 아마도 동일한 링
크로 될 것이다. 그게 아니라면 다른 링크가 있을 것이다. isamchk -ed 로 얼마나 많은 링
크가 있는지 체크할 수 있다. 모든 링크는 isamchk -r 로 제거할 수 있다.(** ?? **)
There is a penalty of 6 bytes for each link. A dynamic record is linked whenever an up
date causes an enlargement of the record. Each new link will be at least 20 bytes, so th
e next enlargement will probably go in the same link. If not, there will be another link.
You may check how many links there are with isamchk -ed. All links may be removed
with isamchk -r.
압축 테이블
- 읽기 전용 테이블은 pack_isam 유틸리티로 만들 수 있다. 확장 mysql 이메일 지원을 구
입한 모든 고객은 내부적인 용도로 pack_isam을 사용할 권리가 주어진다.
- 압축해제 코드는 모든 mysql 배포판에 있으므로 pack_isam이 없는 고객도 pack_isam으
로 압축된 테이블을 읽을 수 있다. (테이블이 같은 플랫폼에서 압축되어 있는한)
- 매우 적은 디스크 용량을 사용.
- 각 레코드는 개별적으로 압축이 된다.( 매우 적은 액세스 overhead) 레코드의 헤더는 테
이블의 가장 큰 레코드에 따라 (1-3 바이트) 고정된다. 각 컬럼은 다르게 압축이 된다. 압축
타입은 다음과 같다:
ㅇ 일반적으로 각 컬럼마다 다른 Huffman 테이블이다.
ㅇ Suffic 공간 압축
ㅇ Prefix 공간 압축
ㅇ 0 값을 가진 숫자는 1비트로 저장.
ㅇ integer 컬럼의 값이 작은 범위를 가졌다면, 컬럼은 최대한 작은 타입으로 저장
된다. 예를 들면 BIGINT 컬럼은 모든 값이 0부터 255라면 TINIINT 컬럼(1바이트)로 저장
된다.
ㅇ 컬럼이 몇가지 가능한 값으로만 구성되어 있다면, 컬럼 타입은 ENUM으로 변환
된다.
ㅇ 컬럼은 위 압축 방법을 조합하여 사용한다.
- 고정 길이나 다이나믹 길이의 테이블을 다룰 수 있다. 그러나 BLOB나 TEXT 컬럼은 다
룰 수 없다.
- isamchk로 압축을 해재할 수 있다.
mysql은 다른 인덱스 타입을 지원한다. 그러나 일반적인 타입은 NISAM이다. 이것은 B-tre
e 인덱스이며 모든 키의 갑을 합하여 (키 길이+4)*0.67로 인덱스 파일의 크기를 대강 계산
할 수 있다. (이것은 모든 키가 정렬된 순서로 입력된 가장 나쁜 경우이다)
String indexes are space compressed. If the first index part is a string, it will also be p
refix compressed. Space compression makes the index file smaller if the string column h
as a lot of trailing space or is a VARCHAR column that is not always used to the full
length. Prefix compression helps if there are many strings with an identical prefix.
문자열 인덱스는 공간이 압축된다. 첫번째 인덱스 부분이 문자열이라면, prefix가 압축된다.
문자열 컬럼이 다량의 trailing space를 가졌거나 언제나 완전한 길이를 사용하지 않는 VA
RCHAR 컬럼일 때 space 압축은 인덱스 파일을 더 작게 만든다. prefix 압축은 많은 문자
열에 동일한 prefix가 있을 때 유용하다.
'DB' 카테고리의 다른 글
| mysql 모니터링하기 (0) | 2007.09.12 |
|---|---|
| mysqladmin 활용 (0) | 2007.09.12 |
| mysql 슬로우 쿼리 확인하기 (0) | 2007.09.12 |
| mysql MYSQL 슬로우 쿼리 mysql slow query 보기 (0) | 2007.09.12 |
| mysqladmin status 및 mysql 퍼포먼스 요소 찾아내기 (0) | 2007.08.28 |
csh과 bash의 차이를 소개하고자 한다.
설명 많이 하는 것보다 소스로 보여준다.
*csh의 특징
set을 쓴다.
expression에서 = 앞뒤로 space를 쓸 수 있다.
배열은 1부터 시작한다.
while 문장은 while() .. end 라는 문법을 가지고 있다.
iteration이 쉽다.
|
#!/bin/csh @ m = 1 |
* bash
expression은 space를 포함지 않는다.
set 안쓴다.
배열의 값은 0부터 시작한다.
배열을 프린트하는 법이 다르다.
배열을 표기하는 법이 다르다.
while [ expression ] do ... done 문법을 사용한다.
expression은 숫자와 문자가 다르게 사용된다.
|
echo "Target Project : ${projects[@]}" echo "Target Project : ${projects[@]}" |
참 봐두라..
*bash의 if문
|
if [ ${IP} == '' ]; then fi |
* bash의 if문 2 (logical OR을 사용시)
| echo ${HOSTS[$m]}" lookup " if [ ${HOSTS[$m]} == '-' ] || [ ${HOSTS[$m]} == ''] then m=`expr $m + 1` continue fi |
'unix and linux' 카테고리의 다른 글
| 파일시스템 타입 보기 (0) | 2007.10.05 |
|---|---|
| 스카시 디스크 장비 보기 (0) | 2007.10.01 |
| bash에서 if문에서 logical or, and를 사용할때 어떻게 사용할까? (0) | 2007.09.11 |
| bash에서 배열 만들기 Tip (0) | 2007.09.11 |
| bash integer 비교 (0) | 2007.09.11 |
슬로우 쿼리 확인하기
| [root@sk4 18:41:08 /env/mysql/data]# mysqladmin -i5 status -u root -p Enter password: Uptime: 682506 Threads: 1 Questions: 1840965 Slow queries: 17742 Opens: 15198 Flush tables: 1 Open tables: 256 Queries per second avg: 2.697 Uptime: 682511 Threads: 1 Questions: 1840965 Slow queries: 17742 Opens: 15198 Flush tables: 1 Open tables: 256 Queries per second avg: 2.697 Uptime: 682516 Threads: 1 Questions: 1840976 Slow queries: 17742 Opens: 15198 Flush tables: 1 Open tables: 256 Queries per second avg: 2.697 Uptime: 682521 Threads: 1 Questions: 1840980 Slow queries: 17742 Opens: 15198 Flush tables: 1 Open tables: 256 Queries per second avg: 2.697 |
'DB' 카테고리의 다른 글
| mysqladmin 활용 (0) | 2007.09.12 |
|---|---|
| mysql 튜닝 관련 (0) | 2007.09.12 |
| mysql MYSQL 슬로우 쿼리 mysql slow query 보기 (0) | 2007.09.12 |
| mysqladmin status 및 mysql 퍼포먼스 요소 찾아내기 (0) | 2007.08.28 |
| mysql에서 쿼리를 파일로 덤프뜨기~ (0) | 2007.08.21 |



카테고리
|
태그목록
최근에 올라온 글
최근에 달린 댓글
최근에 받은 트랙백
글 보관함
달력
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
링크
- Total :
- Today :
- Yesterday :
