|

|
CString Management |
|
CStrings are a useful data type. They greatly simplify a lot of operations in MFC, making it much more convenient to do string manipulation. However, there are some special techniques to using CStrings, particularly hard for people coming from a pure-C background to learn. This essay discusses some of these techniques.
Much of what you need to do is pretty straightforward. This is not a complete tutorial on CStrings, but captures the most common basic questions.
One of the very convenient features of CString is the ability to concatenate two strings. For example if we have
CString gray("Gray");CString cat("Cat");CString graycat = gray + cat;
is a lot nicer than having to do something like:
char gray[] = "Gray";
char cat[] = "Cat";
char * graycat = malloc(strlen(gray) + strlen(cat) + 1);
strcpy(graycat, gray);
strcat(graycat, cat);
Note that the above code is not "Unicode-aware", that is, it only works in compilations of ANSI applications. The correct Unicode-aware representation would be
CString gray(_T("Gray"));CString cat(_T("Cat"));CString graycat = gray + cat;
Formatting (including integer-to-CString)
Rather than using sprintf or wsprintf, you can do formatting for a CString by using the Format method:
CString s;
s.Format(_T("The total is %d"), total);
The advantage here is that you don't have to worry about whether or not the buffer is large enough to hold the formatted data; this is handled for you by the formatting routines.
Use of formatting is the most common way of converting from non-string data types to a CString, for example, converting an integer to a CString:
CString s;
s.Format(_T("%d"), total);
I always use the _T( ) macro because I design my programs to be at least Unicode-aware, but that's a topic for some other essay. The purpose of _T( ) is to compile a string for an 8-bit-character application as:
#define _T(x) x // non-Unicode version
whereas for a Unicode application it is defined as
#define _T(x) L##x // Unicode version
so in Unicode the effect is as if I had written
s.Format(L"%d", total);
If you ever think you might ever possibly use Unicode, start coding in a Unicode-aware fashion. For example, never, ever use sizeof( ) to get the size of a character buffer, because it will be off by a factor of 2 in a Unicode application. We cover Unicode in some detail in Win32 Programming. When I need a size, I have a macro called DIM, which is defined in a file dim.h that I include everywhere:
#define DIM(x) ( sizeof((x)) / sizeof((x)[0]) )
This is not only useful for dealing with Unicode buffers whose size is fixed at compile time, but any compile-time defined table.
class Whatever { ... };
Whatever data[] = {
{ ... },
...
{ ... },
};
for(int i = 0; i < DIM(data); i++) // scan the table looking for a match
Beware of those API calls that want genuine byte counts; using a character count will not work.
TCHAR data[20];
lstrcpyn(data, longstring, sizeof(data) - 1); // WRONG!
lstrcpyn(data, longstring, DIM(data) - 1); // RIGHT
WriteFile(f, data, DIM(data), &bytesWritten, NULL); // WRONG!
WriteFile(f, data, sizeof(data), &bytesWritten, NULL); // RIGHT
This is because lstrcpyn wants a character count, but WriteFile wants a byte count. Also note that this always writes out the entire contents of data. If you only want to write out the actual length of the data, you would think you might do
WriteFile(f, data, lstrlen(data), &bytesWritten, NULL); // WRONG
but that will not work in a Unicode application. Instead, you must do
WriteFile(f, data, lstrlen(data) * sizeof(TCHAR), &bytesWritten, NULL); // RIGHT
because WriteFile wants a byte count. (For those of you who might be tempted to say "but that means I'll always be multiplying by 1 for ordinary applications, and that is inefficient", you need to understand what compilers actually do. No real C or C++ compiler would actually compile a multiply instruction inline; the multiply-by-one is simply discarded by the compiler as being a silly thing to do. And if you think when you use Unicode that you'll have to pay the cost of multiplying by 2, remember that this is just a bit-shift left by 1 bit, which the compiler is also happy to do instead of the multiplication).
Using _T does not create a Unicode application. It creates a Unicode-aware application. When you compile in the default 8-bit mode, you get a "normal" 8-bit program; when you compile in Unicode mode, you get a Unicode (16-bit-character) application. Note that a CString in a Unicode application is a string that holds 16-bit characters.
The simplest way to convert a CString to an integer value is to use one of the standard string-to-integer conversion routines.
While generally you will suspect that _atoi is a good choice, it is rarely the right choice. If you play to be Unicode-ready, you should call the function _ttoi, which compiles into _atoi in ANSI code and _wtoi in Unicode code. You can also consider using _tcstoul (for unsigned conversion to any radix, such as 2, 8, 10 or 16) or _tcstol (for signed conversion to any radix). For example, here are some examples:
CString hex = _T("FAB");CString decimal = _T("4011");ASSERT(_tcstoul(hex, 0, 16) == _ttoi(decimal));
This is the most common set of questions beginners have on the CString data type. Due largely to serious C++ magic, you can largely ignore many of the problems. Things just "work right". The problems come about when you don't understand the basic mechanisms and then don't understand why something that seems obvious doesn't work.
For example, having noticed the above example you might wonder why you can't write
CString graycat = "Gray" + "Cat";
or
CString graycat("Gray" + "Cat");
In fact the compiler will complain bitterly about these attempts. Why? Because the + operator is defined as an overloaded operator on various combinations of the CString and LPCTSTR data types, but not between two LPCTSTR data types, which are underlying data types. You can't overload C++ operators on base types like int and char, or char *. What will work is
CString graycat = CString("Gray") + CString("Cat");
or even
CString graycat = CString("Gray") + "Cat";
If you study these, you will see that the + always applies to at least one CString and one LPCSTR.
Note that it is always better to write Unicode-aware code, e.g.,
CString graycat = CString(_T("Gray")) + _T("Cat");
and so on. This makes your code immediately portable.
So you have a char *, or a string. How do you create a CString. Here are some examples:
char * p = "This is a test"
or, in Unicode-aware applications
TCHAR * p = _T("This is a test")
or
LPTSTR p = _T("This is a test");
you can write any of the following:
CString s = "This is a test"; // 8-bit only
CString s = _T("This is a test"); // Unicode-awareCString s("This is a test"); // 8-bit onlyCString s(_T("This is a test")); // Unicode-awareCString s = p;
CString s(p);
Any of these readily convert the constant string or the pointer to a CString value. Note that the characters assigned are always copied into the CString so that you can do something like
TCHAR * p = _T("Gray");CString s(p);
p = _T("Cat");s += p;
and be sure that the resulting string is "GrayCat".
There are several other methods for CString constructors, but we will not consider most of these here; you can read about them on your own.
Actually, it is a bit subtler than I show. For example
CString s = "This is a test";
is sloppy programming, but actually will compile correctly for Unicode. What it does is invoke the MultiByteToWideChar operation of the CString constructor to convert, at run-time, the 8-bit character string to a 16-bit Unicode character string. However, this can still be useful if the char * pointer refers, for example, to 8-bit data that just came in over the network.
This is a slightly harder transition to find out about, and there is lots of confusion about the "right" way to do it. There are quite a few right ways, and probably an equal number of wrong ways.
The first thing you have to understand about a CString is that it is a special C++ object which contains three values: a pointer to a buffer, a count of the valid characters in the buffer, and a buffer length. The count of the number of characters can be any size from 0 up to the maximum length of the buffer minus one (for the NUL byte). The character count and buffer length are cleverly hidden.
Unless you do some special things, you know nothing about the size of the buffer that is associated with the CString. Therefore, if you can get the address of the buffer, you cannot change its contents. You cannot shorten the contents, and you absolutely must not lengthen the contents. This leads to some at-first-glance odd workarounds.
The operator LPCTSTR (or more specifically, the operator const TCHAR *), is overloaded for CString. The definition of the operator is to return the address of the buffer. Thus, if you need a string pointer to the CString you can do something like
CString s("GrayCat");LPCTSTR p = s;
and it works correctly. This is because of the rules about how casting is done in C; when a cast is required, C++ rules allow the cast to be selected. For example, you could define (float) as a cast on a complex number (a pair of floats) and define it to return only the first float (called the "real part") of the complex number so you could say
Complex c(1.2f, 4.8f);
float realpart = c;
and expect to see, if the (float) operator is defined properly, that the value of realpart is now 1.2.
This works for you in all kinds of places. For example, any function that takes an LPCTSTR parameter will force this coercion, so that you can have a function (perhaps in a DLL you bought):
BOOL DoSomethingCool(LPCTSTR s);
and call it as follows
CString file("c:\\myfiles\\coolstuff")BOOL result = DoSomethingCool(file);
This works correctly because the DoSomethingCool function has specified that it wants an LPCTSTR and therefore the LPCTSTR operator is applied to the argument, which in MFC means that the address of the string is returned.
But what if you want to format it?
CString graycat("GrayCat");CString s;
s.Format("Mew! I love %s", graycat);
Note that because the value appears in the variable-argument list (the list designated by "..." in the specification of the function) that there is no implicit coercion operator. What are you going to get?
Well, surprise, you actually get the string
"Mew! I love GrayCat"
because the MFC implementers carefully designed the CString data type so that an expression of type CString evaluates to the pointer to the string, so in the absence of any casting, such as in a Format or sprintf, you will still get the correct behavior. The additional data that describes a CString actually lives in the addresses below the nominal CString address.
What you can't do is modify the string. For example, you might try to do something like replace the "." by a "," (don't do it this way, you should use the National Language Support features for decimal conversions if you care about internationalization, but this makes a simple example):
CString v("1.00"); // currency amount, 2 decimal placesLPCTSTR p = v;
p[lstrlen(p) - 3] = ',';
If you try to do this, the compiler will complain that you are assigning to a constant string. This is the correct message. It would also complain if you tried
strcat(p, "each");
because strcat wants an LPTSTR as its first argument and you gave it an LPCTSTR.
Don't try to defeat these error messages. You will get yourself into trouble!
The reason is that the buffer has a count, which is inaccessible to you (it's in that hidden area that sits below the CString address), and if you change the string, you won't see the change reflected in the character count for the buffer. Furthermore, if the string happens to be just about as long as the buffer physical limit (more on this later), an attempt to extend the string will overwrite whatever is beyond the buffer, which is memory you have no right to write (right?) and you'll damage memory you don't own. Sure recipe for a dead application.
A special method is available for a CString if you need to modify it. This is the operation GetBuffer. What this does is return to you a pointer to the buffer which is considered writeable. If you are only going to change characters or shorten the string, you are now free to do so:
CString s(_T("File.ext"));LPTSTR p = s.GetBuffer();
LPTSTR dot = strchr(p, '.'); // OK, should have used s.Find...
if(p != NULL)
*p = _T('\0');s.ReleaseBuffer();
This is the first and simplest use of GetBuffer. You don't supply an argument, so the default of 0 is used, which means "give me a pointer to the string; I promise to not extend the string". When you call ReleaseBuffer, the actual length of the string is recomputed and stored in the CString. Within the scope of a GetBuffer/ReleaseBuffer sequene, and I emphasize this: You Must Not, Ever, Use Any Method Of CString on the CString whose buffer you have! The reason for this is that the integrity of the CString object is not guaranteed until the ReleaseBuffer is called. Study the code below:
CString s(...);
LPTSTR p = s.GetBuffer();
//... lots of things happen via the pointer p
int n = s.GetLength(); // BAD!!!!! PROBABLY WILL GIVE WRONG ANSWER!!!
s.TrimRight(); // BAD!!!!! NO GUARANTEE IT WILL WORK!!!!
s.ReleaseBuffer(); // Things are now OK
int m = s.GetLength(); // This is guaranteed to be correct
s.TrimRight(); // Will work correctly
Suppose you want to actually extend the string. In this case you must know how large the string will get. This is just like declaring
char buffer[1024];
knowing that 1024 is more than enough space for anything you are going to do. The equivalent in the CString world is
LPTSTR p = s.GetBuffer(1024);
This call gives you not only a pointer to the buffer, but guarantees that the buffer will be (at least) 1024 characters in length. (Note I said "characters", not "bytes", because CString is Unicode-aware implicitly).
Also, note that if you have a pointer to a const string, the string value itself is stored in read-only memory; an attempt to store into it, even if you've done GetBuffer, you have a pointer to read-only memory, so an attempt to store into the string will fail with an access error. I haven't verified this for CString, but I've seen ordinary C programmers make this error frequently.
A common "bad idiom" left over from C programmers is to allocate a buffer of fixed size, do a sprintf into it, and assign it to a CString:
char buffer[256];
sprintf(buffer, "%......", args, ...); // ... means "lots of stuff here"
CString s = buffer;
while the better form is to do
CString s;
s.Format(_T("%...."), args, ...);
Note that this always works; if your string happens to end up longer than 256 bytes you don't clobber the stack!
Another common error is to be clever and realize that a fixed size won't work, so the programmer allocates bytes dynamically. This is even sillier:
int len = lstrlen(parm1) + 13 + lstrlen(parm2) + 10 + 100;
char * buffer = new char[len];
sprintf(buffer, "%s is equal to %s, valid data", parm1, parm2);
CString s = buffer;
....
delete [] buffer;
Where it can be easily written as
CString s;
s.Format(_T("%s is equal to %s, valid data"), parm1, parm2);
Note that the sprintf examples are not Unicode-ready (although you could use tsprintf and put _T() around the formatting string, but the basic idea is still that you are doing far more work than is necessary, and it is error-prone.
A very common operation is to pass a CString value in to a control, for example, a CTreeCtrl. While MFC provides a number of convenient overloads for the operation, but in the most general situation you use the "raw" form of the update, and therefore you need to store a pointer to a string in the TVITEM which is included within the TVINSERTITEMSTRUCT:
TVINSERTITEMSTRUCT tvi;
CString s;
// ... assign something to s
tvi.item.pszText = s; // Compiler yells at you here
// ... other stuff
HTREEITEM ti = c_MyTree.InsertItem(&tvi);
Now why did the compiler complain? It looks like a perfectly good assignment! But in fact if you look at the structure, you will see that the member is declared in the TVITEM structure as shown below:
LPTSTR pszText;
int cchTextMax;
Therefore, the assignment is not assigning to an LPCTSTR and the compiler has no idea how to cast the right hand side of the assignment to an LPTSTR.
OK, you say, I can deal with that, and you write
tvi.item.pszText = (LPCTSTR)s; // compiler still complains!
What the compiler is now complaining about is that you are attempting to assign an LPCTSTR to an LPTSTR, an operation which is forbidden by the rules of C and C++. You may not use this technique to accidentally alias a constant pointer to a non-constant alias so you can violate the assumptions of constancy. If you could, you could potentially confuse the optimizer, which trusts what you tell it when deciding how to optimize your program. For example, if you do
const int i = ...;
//... do lots of stuff
... = a[i]; // usage 1
// ... lots more stuff
... = a[i]; // usage 2
Then the compiler can trust that, because you said const, that the value of i at "usage1" and "usage2" is the same value, and it can even precompute the address of a[i] at usage1 and keep the value around for later use at usage2, rather than computing it each time. If you were able to write
const int i = ...;
int * p = &i;
//... do lots of stuff
... = a[i]; // usage 1
// ... lots more stuff
(*p)++; // mess over compiler's assumption
// ... and other stuff
... = a[i]; // usage 2
The the compiler would believe in the constancy of i, and consequently the constancy of the location of a[i], and the place where the indirection is done destroys that assumption. Thus, the program would exhibit one behavior when compiled in debug mode (no optimizations) and another behavior when compiled in release mode (full optimization). This Is Not Good. Therefore, the attempt to assign the pointer to i to a modifiable reference is diagnosed by the compiler as being bogus. This is why the (LPCTSTR) cast won't really help.
Why not just declare the member as an LPCTSTR? Because the structure is used both for reading and writing to the control. When you are writing to the control, the text pointer is actually treated as an LPCTSTR but when you are reading from the control you need a writeable string. The structure cannot distinguish its use for input from its use for output.
Therefore, you will often find in my code something that looks like
tvi.item.pszText = (LPTSTR)(LPCTSTR)s;
This casts the CString to an LPCTSTR, thus giving me that address of the string, which I then force to be an LPTSTR so I can assign it. Note that this is valid only if you are using the value as data to a Set or Insert style method! You cannot do this when you are trying to retrieve data!
You need a slightly different method when you are trying to retrieve data, such as the value stored in a control. For example, for a CTreeCtrl using the GetItem method. Here, I want to get the text of the item. I know that the text is no more than MY_LIMIT in size. Therefore, I can write something like
TVITEM tvi;
// ... assorted initialization of other fields of tvi
tvi.pszText = s.GetBuffer(MY_LIMIT);
tvi.cchTextMax = MY_LIMIT;
c_MyTree.GetItem(&tvi);
s.ReleaseBuffer();
Note that the code above works for any type of Set method also, but is not needed because for a Set-type method (including Insert) you are not writing the string. But when you are writing the CString you need to make sure the buffer is writeable. That's what the GetBuffer does. Again, note that once you have done the GetBuffer call, you must not do anything else to the CString until the ReleaseBuffer call.
When programming with ActiveX, you will sometimes need a value represented as a type BSTR. A BSTR is a counted string, a wide-character (Unicode) string on Intel platforms and can contain embedded NUL characters.
You can convert at CString to a BSTR by calling the CString method AllocSysString:
CString s;
s = ... ; // whatever
BSTR b = s.AllocSysString();
The pointer b points to a newly-allocated BSTR object which is a copy of the CString, including the terminal NUL character. This may now be passed to whatever interface you are calling that requires a BSTR. Normally, a BSTR is disposed of by the component receiving it. If you should need to dispose of a BSTR, you must use the call
::SysFreeString(b);
to free the string.
The story is that the decision of how to represent strings sent to ActiveX controls resulted in some serious turf wars within Microsoft. The Visual Basic people won, and the string type BSTR (acronym for "Basic String") was the result.
Since a BSTR is a counted Unicode string, you can use standard conversions to make an 8-bit CString. Actually, this is built-in; there are special constructors for converting ANSI strings to Unicode and vice-versa. You can also get BSTRs as results in a VARIANT type, which is a type returned by various COM and Automation calls.
For example, if you do, in an ANSI application,
BSTR b;
b = ...; // whatever
CString s(b == NULL ? L"" : b)
works just fine for a single-string BSTR, because there is a special constructor that takes an LPCWSTR (which is what a BSTR is) and converts it to an ANSI string. The special test is required because a BSTR could be NULL, and the constructors Don't Play Well with NULL inputs (thanks to Brian Ross for pointing this out!). This also only works for a BSTR that contains only a single string terminated with a NUL; you have to do more work to convert strings that contain multiple NUL characters. Note that embedded NUL characters generally don't work well in CStrings and generally should be avoided.
Remember, according to the rules of C/C++, if you have an LPWSTR it will match a parameter type of LPCWSTR (it doesn't work the other way!).
In UNICODE mode, this is just the constructor
CString::CString(LPCTSTR);
As indicated above, in ANSI mode there is a special constructor for
CString::CString(LPCWSTR);
this calls an internal function to convert the Unicode string to an ANSI string. (In Unicode mode there is a special constructor that takes an LPCSTR, a pointer to an 8-bit ANSI string, and widens it to a Unicode string!). Again, note the limitation imposed by the need to test for a BSTR value which is NULL.
There is an additional problem as pointed out above: BSTRs can contain embedded NUL characters; CString constructors can only handle single NUL characters in a string. This means that CStrings will compute the wrong length for a string which contains embedded NUL bytes. You need to handle this yourself. If you look at the constructors in strcore.cpp, you will see that they all do an lstrlen or equivalent to compute the length.
Note that the conversion from Unicode to ANSI uses the ::WideCharToMultiByte conversion with specific arguments that you may not like. If you want a different conversion than the default, you have to write your own.
If you are compiling as UNICODE, then it is a simple assignment:
CString convert(BSTR b)
{
if(b == NULL)
return CString(_T(""));
CString s(b); // in UNICODE mode
return s;
}
If you are in ANSI mode, you need to convert the string in a more complex fashion. This will accomplish it. Note that this code uses the same argument values to ::WideCharToMultiByte that the implicit constructor for CString uses, so you would use this technique only if you wanted to change these parameters to do the conversion in some other fashion, for example, specifying a different default character, a different set of flags, etc.
CString convert(BSTR b)
{
CString s;
if(b == NULL)
return s; // empty for NULL BSTR
#ifdef UNICODE
s = b;
#else
LPSTR p = s.GetBuffer(SysStringLen(b) + 1);
::WideCharToMultiByte(CP_ACP, // ANSI Code Page
0, // no flags
b, // source widechar string
-1, // assume NUL-terminated
p, // target buffer
SysStringLen(b)+1, // target buffer length
NULL, // use system default char
NULL); // don't care if default used
s.ReleaseBuffer();
#endif
return s;
}
Note that I do not worry about what happens if the BSTR contains Unicode characters that do not map to the 8-bit character set, because I specify NULL as the last two parameters. This is the sort of thing you might want to change.
Actually, I've never done this; I don't work in COM/OLE/ActiveX where this is an issue. But I saw a posting by Robert Quirk on the microsoft.public.vc.mfc newsgroup on how to do this, and it seemed silly not to include it in this essay, so here it is, with a bit more explanation and elaboration. Any errors relative to what he wrote are my fault.
A VARIANT is a generic parameter/return type in COM programming. You can write methods that return a type VARIANT, and which type the function returns may (and often does) depend on the input parameters to your method (for example, in Automation, depending on which method you call, IDispatch::Invoke may return (via one of its parameters) a VARIANT which holds a BYTE, a WORD, an float, a double, a date, a BSTR, and about three dozen other types (see the specifications of the VARIANT structure in the MSDN). In the example below, it is assumed that the type is known to be a variant of type BSTR, which means that the value is found in the string referenced by bstrVal. This takes advantage of the fact that there is a constructor which, in an ANSI application, will convert a value referenced by an LPCWCHAR to a CString (see BSTR-to-CString). In Unicode mode, this turns out to be the normal CString constructor. See the caveats about the default ::WideCharToMultibyte conversion and whether or not you find these acceptable (mostly, you will).
VARIANT vaData;
vaData = m_com.YourMethodHere();
ASSERT(vaData.vt == VT_BSTR);
CString strData(vaData.bstrVal);
Note that you could also make a more generic conversion routine that looked at the vt field. In this case, you might consider something like:
CString VariantToString(VARIANT * va)
{
CString s;
switch(va->vt)
{ /* vt */
case VT_BSTR:
return CString(vaData->bstrVal);
case VT_BSTR | VT_BYREF:
return CString(*vaData->pbstrVal);
case VT_I4:
s.Format(_T("%d"), va->lVal);
return s;
case VT_I4 | VT_BYREF:
s.Format(_T("%d"), *va->plVal);
case VT_R8:
s.Format(_T("%f"), va->dblVal);
return s;
... remaining cases left as an Exercise For The Reader
default:
ASSERT(FALSE); // unknown VARIANT type (this ASSERT is optional)
return CString("");
} /* vt */
}
If you want to create a program that is easily ported to other languages, you must not include native-language strings in your source code. (For these examples, I'll use English, since that is my native language (aber Ich kann ein bischen Deutsch sprechen). So it is very bad practice to write
CString s = "There is an error";
Instead, you should put all your language-specific strings (except, perhaps, debug strings, which are never in a product deliverable). This means that is fine to write
s.Format(_T("%d - %s"), code, text);
in your program; that literal string is not language-sensitive. However, you must be very careful to not use strings like
// fmt is "Error in %s file %s"
// readorwrite is "reading" or "writing"
s.Format(fmt, readorwrite, filename);
I speak of this from experience. In my first internationalized application I made this error, and in spite of the fact that I know German, and that German word order places the verb at the end of a sentence, I had done this. Our German distributor complained bitterly that he had to come up with truly weird error messages in German to get the format codes to do the right thing. It is much better (and what I do now) to have two strings, one for reading and one for writing, and load the appropriate one, making them string parameter-insensitive, that is, instead of loading the strings "reading" or "writing", load the whole format:
// fmt is "Error in reading file %s"
// "Error in writing file %s"
s.Format(fmt, filename);
Note that if you have more than one substitution, you should make sure that if the word order of the substitutions does not matter, for example, subject-object, subject-verb, or verb-object, in English.
For now, I won't talk about FormatMessage, which actually is better than sprintf/Format, but is poorly integrated into the CString class. It solves this by naming the parameters by their position in the parameter list and allows you to rearrange them in the output string.
So how do we accomplish all this? By storing the string values in the resource known as the STRINGTABLE in the resource segment. To do this, you must first create the string, using the Visual Studio resource editor. A string is given a string ID, typically starting IDS_. So you have a message, you create the string and call it IDS_READING_FILE and another called IDS_WRITING_FILE. They appear in your .rc file as
STRINGTABLE
IDS_READING_FILE "Reading file %s"
IDS_WRITING_FILE "Writing file %s"
END
Note: these resources are always stored as Unicode strings, no matter what your program is compiled as. They are even Unicode strings on Win9x platforms, which otherwise have no real grasp of Unicode (but they do for resources!). Then you go to where you had stored the strings
// previous code
CString fmt;
if(...)
fmt = "Reading file %s";
else
fmt = "Writing file %s";
...
// much later
CString s;
s.Format(fmt, filename);
and instead do
// revised code
CString fmt;
if(...)
fmt.LoadString(IDS_READING_FILE);
else
fmt.LoadString(DS_WRITING_FILE);
...
// much later
CString s;
s.Format(fmt, filename);
Now your code can be moved to any language. The LoadString method takes a string ID and retrieves the STRINGTABLE value it represents, and assigns that value to the CString.
There is a clever feature of the CString constructor that simplifies the use of STRINGTABLE entries. It is not explicitly documented in the CString::CString specification, but is obscurely shown in the example usage of the constructor! (Why this couldn't be part of the formal documentation and has to be shown in an example escapes me!). The feature is that if you cast a STRINGTABLE ID to an LPCTSTR it will implicitly do a LoadString. Thus the following two examples of creating a string value produce the same effect, and the ASSERT will not trigger in debug mode compilations:
CString s;
s.LoadString(IDS_WHATEVER);
CString t( (LPCTSTR)IDS_WHATEVER);
ASSERT(s == t);
Now, you may say, how can this possibly work? How can it tell a valid pointer from a STRINGTABLE ID? Simple: all string IDs are in the range 1..65535. This means that the high-order bits of the pointer will be 0. Sounds good, but what if I have valid data in a low address? Well, the answer is, you can't. The lower 64K of your address space will never, ever, exist. Any attempt to access a value in the address range 0x00000000 through 0x0000FFFF (0..65535) will always and forever give an access fault. These addresses are never, ever valid addresses. Thus a value in that range (other than 0) must necessarily represent a STRINGTABLE ID.
I tend to use the MAKEINTRESOURCE macro to do the casting. I think it makes the code clearer regarding what is going on. It is a standard macro which doesn't have much applicability otherwise in MFC. You may have noted that many methods take either a UINT or an LPCTSTR as parameters, using C++ overloading. This gets us around the ugliness of pure C where the "overloaded" methods (which aren't really overloaded in C) required explicit casts. This is also useful in assigning resource names to various other structures.
CString s;
s.LoadString(IDS_WHATEVER);
CString t( MAKEINTRESOURCE(IDS_WHATEVER));
ASSERT(s == t);
Just to give you an idea: I practice what I preach here. You will rarely if ever find a literal string in my program, other than the occasional debug output messages, and, of course, any language-independent string.
Here's a little problem that came up on the microsoft.public.vc.mfc newsgroup a while ago. I'll simplify it a bit. The basic problem was the programmer wanted to write a string to the Registry. So he wrote:
I am trying to set a registry value using RegSetValueEx() and it is the value that I am having trouble with. If I declare a variable of char[] it works fine. However, I am trying to convert from a CString and I get garbage. "ÝÝÝÝ...ÝÝÝÝÝÝ" to be exact. I have tried GetBuffer, typecasting to char*, LPCSTR. The return of GetBuffer (from debug) is the correct string but when I assign it to a char* (or LPCSTR) it is garbage. Following is a piece of my code:
char* szName = GetName().GetBuffer(20);
RegSetValueEx(hKey, "Name", 0, REG_SZ,
(CONST BYTE *) szName,
strlen (szName + 1));
The Name string is less then 20 chars long, so I don't think the GetBuffer parameter is to blame.
It is very frustrating and any help is appreciated.
Dear Frustrated,
You have been done in by a fairly subtle error, caused by trying to be a bit too clever. What happened was that you fell victim to knowing too much. The correct code is shown below:
CString Name = GetName();
RegSetValueEx(hKey, _T("Name"), 0, REG_SZ,
(CONST BYTE *) (LPCTSTR)Name,
(Name.GetLength() + 1) * sizeof(TCHAR));
Here's why my code works and yours didn't. When your function GetName returned a CString, it returned a "temporary object". See the C++ Reference manual §12.2.
In some circumstances it may be necessary or convenient for the compiler to generate a temporary object. Such introduction of temporaries is implementation dependent. When a compiler introduces a temporary object of a class that has a constructor it must ensure that a construct is called for the temporary object. Similarly, the destructor must be called for a temporary object of a class where a destructor is declared.
The compiler must ensure that a temporary object is destroyed. The exact point of destruction is implementation dependent....This destruction must take place before exit from the scope in which the temporary is created.
Most compilers implement the implicit destructor for a temporary at the next program sequencing point following its creation, that is, for all practical purposes, the next semicolon. Hence the CString existed when the GetBuffer call was made, but was destroyed following the semicolon. (As an aside, there was no reason to provide an argument to GetBuffer, and the code as written is incorrect since there is no ReleaseBuffer performed). So what GetBuffer returned was a pointer to storage for the text of the CString. When the destructor was called at the semicolon, the basic CString object was freed, along with the storage that had been allocated to it. The MFC debug storage allocator then rewrites this freed storage with 0xDD, which is the symbol "Ý". By the time you do the write to the Registry, the string contents have been destroyed.
There is no particular reason to need to cast the result to a char * immediately. Storing it as a CString means that a copy of the result is made, so after the temporary CString is destroyed, the string still exists in the variable's CString. The casting at the time of the Registry call is sufficient to get the value of a string which already exists.
In addition, my code is Unicode-ready. The Registry call wants a byte count. Note also that the call lstrlen(Name+1) returns a value that is too small by 2 for an ANSI string, since it doesn't start until the second character of the string. What you meant to write was lstrlen(Name) + 1 (OK, I admit it, I've made the same error!). However, in Unicode, where all characters are two bytes long, we need to cope with this. The Microsoft documentation is surprisingly silent on this point: is the value given for REG_SZ values a byte count or a character count? I'm assuming that their specification of "byte count" means exactly that, and you have to compensate.
One problem of CString is that it hides certain inefficiencies from you. On the other hand, it also means that it can implement certain efficiencies. You may be tempted to say of the following code
CString s = SomeCString1;
s += SomeCString2;
s += SomeCString3;
s += ",";
s += SomeCString4;
that it is horribly inefficient compared to, say
char s[1024];
lstrcpy(s, SomeString1);
lstrcat(s, SomeString2);
lstrcat(s, SomeString 3);
lstrcat(s, ",");
lstrcat(s, SomeString4);
After all, you might think, first it allocates a buffer to hold SomeCString1, then copies SomeCString1 to it, then detects it is doing a concatenate, allocates a new buffer large enough to hold the current string plus SomeCString2, copies the contents to the buffer and concatenates the SomeCString2 to it, then discards the first buffer and replaces the pointer with a pointer to the new buffer, then repeats this for each of the strings, being horribly inefficient with all those copies.
The truth is, it probably never copies the source strings (the left side of the +=) for most cases.
In VC++ 6.0, in Release mode, all CString buffers are allocated in predefined quanta. These are defined as 64, 128, 256, and 512 bytes. This means that unless the strings are very long, the creation of the concatenated string is an optimized version of a strcat operation (since it knows the location of the end of the string it doesn't have to search for it, as strcat would; it just does a memcpy to the correct place) plus a recomputation of the length of the string. So it is about as efficient as the clumsier pure-C code, and one whole lot easier to write. And maintain. And understand.
Those of you who aren't sure this is what is really happening, look in the source code for CString, strcore.cpp, in the mfc\src subdirectory of your vc98 installation. Look for the method ConcatInPlace which is called from all the += operators.
Aha! So CString isn't really "efficient!" For example, if I create
CString cat("Mew!");
then I don't get a nice, tidy little buffer 5 bytes long (4 data bytes plus the terminal NUL). Instead the system wastes all that space by giving me 64 bytes and wasting 59 of them.
If this is how you think, be prepared to reeducate yourself. Somewhere in your career somebody taught you that you always had to use as little space as possible, and this was a Good Thing.
This is incorrect. It ignores some seriously important aspects of reality.
If you are used to programming embedded applications with 16K EPROMs, you have a particular mindset for doing such allocation. For that application domain, this is healthy. But for writing Windows applications on 500MHz, 256MB machines, it actually works against you, and creates programs that perform far worse than what you would think of as "less efficient" code.
For example, size of strings is thought to be a first-order effect. It is Good to make this small, and Bad to make it large. Nonsense. The effect of precise allocation is that after a few hours of the program running, the heap is cluttered up with little tiny pieces of storage which are useless for anything, but they increase the storage footprint of your application, increase paging traffic, can actually slow down the storage allocator to unacceptable performance levels, and eventually allow your application to grow to consume all of available memory. Storage fragmentation, a second-order or third-order effect, actually dominates system performance. Eventually, it compromises reliability, which is completely unacceptable.
Note that in Debug mode compilations, the allocation is always exact. This helps shake out bugs.
Assume your application is going to run for months at a time. For example, I bring up VC++, Word, PowerPoint, FrontPage, Outlook Express, Forté Agent, Internet Explorer, and a few other applications, and essentially never close them. I've edited using PowerPoint for days on end (on the other hand, if you've had the misfortune to have to use something like Adobe FrameMaker, you begin to appreciate reliability; I've rarely been able to use this application without it crashing four to six times a day! And always because it has run out of space, usually by filling up my entire massive swap space!) Precise allocation is one of the misfeatures that will compromise reliability and lead to application crashes.
By making CStrings be multiples of some quantum, the memory allocator will end up cluttered with chunks of memory which are almost always immediately reusable for another CString, so the fragmentation is minimized, allocator performance is enhanced, application footprint remains almost as small as possible, and you can run for weeks or months without problem.
Aside: Many years ago, at CMU, we were writing an interactive system. Some studies of the storage allocator showed that it had a tendency to fragment memory badly. Jim Mitchell, now at Sun Microsystems, created a storage allocator that maintained running statistics about allocation size, such as the mean and standard deviation of all allocations. If a chunk of storage would be split into a size that was smaller than the mean minus one s than the prevailing allocation, he didn't split it at all, thus avoiding cluttering up the allocator with pieces too small to be usable. He actually used floating point inside an allocator! His observation was that the long-term saving in instructions by not having to ignore unusable small storage chunks far and away exceeded the additional cost of doing a few floating point operations on an allocation operation. He was right.
Never, ever think about "optimization" in terms of small-and-fast analyzed on a per-line-of-code basis. Optimization should mean small-and-fast analyzed at the complete application level (if you like New Age buzzwords, think of this as the holistic approach to program optimization, a whole lot better than the per-line basis we teach new programmers). At the complete application level, minimum-chunk string allocation is about the worst method you could possibly use.
If you think optimization is something you do at the code-line level, think again. Optimization at this level rarely matters. Read my essay on Optimization: Your Worst Enemy for some thought-provoking ideas on this topic.
Note that the += operator is special-cased; if you were to write:
CString s = SomeCString1 + SomeCString2 + SomeCString3 + "," + SomeCString4;
then each application of the + operator causes a new string to be created and a copy to be done (although it is an optimized version, since the length of the string is known and the inefficiencies of strcat do not come into play).
There are two different issues in dealing with Unicode and CStrings. In VS6, the CString takes on the data type of the TCHAR type; that is, in an "ANSI" application a CString holds only 8-bit characters and in a Unicode app a CString holds only Unicode (16-bit) characters. If you have to "mix and match" you are out of luck. In some cases, this forces you to compile as a Unicode app, use Unicode everywhere, and "down-convert" the Unicode characters to 8-bit characters before sending them out, and "up-convert" incoming character streams to Unicode.
This isn't always a Bad Thing; for example, if the incoming characters were in UTF-7 or UTF-8 encoding, then Unicode is actually the "natural" representation of those characters, and only the transport layer is concerned about the transmittal as 8-bit characters.
In VS.NET, however, we have more degrees of flexibility. In addition to the CString data type, which follows the same rules as VS6, there are two new data types, CStringA and CStringW. A CStringA string always holds 8-bit characters independent of the compilation mode of the program, and a CStringW always holds Unicode characters, independent of the compilation mode of the program.
One of the questions that arises often is "How do I..." and followed by a question of how to handle 8-bit characters in a Unicode app or Unicode characters in an 8-bit app.
In VS6, this is not easy. You will have to explicitly convert the strings to the form of your app. I have found vastly fewer problems if I build the apps as Unicode apps and up-convert any 8-bit strings on input and down-convert if 8-bit output is required. This allows me to keep everything internally in a single, uniform representation. If you have coded your app "Unicode-aware" from the start, you can simply set the UNICODE/_UNICODE options and your app will come out Unicode-ready; then all you do is modify the 8-bit input and output locations to do the conversion. But if you require the app remain 8-bit, then the "not easy" part comes into play. I have found that instead of using TCHAR * arrays which are explicitly allocated and freed, I prefer to use CArray, e.g., typedef CArray<WCHAR, WCHAR> CWCharArray, which gives me the advantages of CString in terms of allocation and deallocation but is still, frankly, a real pain to use the rest of the time if you need string operations; you will end up using the wcs... operations far too often. But doing this I find fewer storage leaks occur, because the CArray is properly destroyed when its containing object is destroyed.
If you are forced to do wcsspy or wcscat, you should rethink what you are doing to use the strsafe.h library and use StringCchCopy or StringCchCat. These are macros, like CreateFile, so the underlying functions have names like StringCchCopyA and StringCchCopyW which you can call explicitly. You need a recent release of the Platform SDK to get these functions and their libraries.
You should also look into the ATL macros for character conversions. In some cases, where the default codepage is all that is needed, these will suffice. However, it seems more common, at least in the code I write, to need explicit UTF-8 conversions.
In VS.NET, it is easier; what the table below is going to show is some ways of doing conversions between input/output representations and internal representations. I am going to write the table in terms of CStringA and CStringW. For VS6, this will require knowing which mode you have compiled in, and select an alternate representation for the "other" format. For example, if you are compiling an ANSI app, then CString represents 8-bit strings, and CWCharArray (see the earlier paragraph in this section) represents 16-bit strings. If you are compiling Unicode app, then CString represents 16-bit strings and CByteArray represents 8-bit strings. This is one reason that I don't try to build apps in VS6 that handle both 8-bit and 16-bit representations but could be compiled in either mode. I just make them Unicode apps from the start, and that way I only have one conversion issue to deal with, and strings are easier to use.
| Converting To ê |
Converting From è |
8-bit ACP byte stream |
8-bit non-ACP byte stream |
| CStringA |
LPCSTR acp = ...;
CStringA s = acp;
or LPCSTR acp;
CStringA s(acp); |
LPCSTR acp = ...;
CStringA s = acp;
or LPCSTR acp;
CStringA s(acp); |
| CStringW |
LPCSTR acp = ...; or CStringA acp = ...;
then int n = ::MultiByteToWideChar(CP_ACP, 0, acp, -1, NULL, 0);
CStringW s;
LPWSTR p = s.GetBuffer(n);
::MultiByteToWideChar(CP_ACP, 0, acp, -1, p, n);
s.ReleaseBuffer(); |
LPCSTR acp = ...;
or CStringA acp = ...;
then int n = ::MultiByteToWideChar(CP_OF_YOUR_CHOICE, 0, acp, -1, NULL, 0);
CString W s;
LPWSTR p = s.GetBuffer(n);
::MultiByteToWideChar(CP_ACP, 0, acp, -1, p, n);
s.ReleaseBuffer(); |
| CString (VS6, ANSI mode) |
LPCSTR acp = ...;
CString s = acp;
or LPCSTR acp = ...;
CString s(acp); |
LPCSTR acp = ...;
CString s = acp;
or LPCSTR acp = ...;
CString s(acp); |
| CString (VS6, Unicode mode) |
LPCSTR acp = ...;
int n = ::MultiByteToWideChar(CP_ACP, 0, acp, -1, NULL, 0);
CString s;
LPWSTR p = s.GetBuffer(n);
::MultiByteToWideChar(CP_ACP, 0, acp, -1, p, n);
s.ReleaseBuffer(); or CArray<char, char> acp;
// e.g.
// acp.SetSize(n);
// ReadFile(h, acp.GetBuffer(), n, NULL);
then CString s(acp.GetData());
or CString s;
int n = ::MultiByteToWideChar(CP_ACP, 0, acp.GetBuffer(), -1, NULL, 0);
LPWSTR p = s.GetBuffer(n);
::MultiByteToWideChar(CP_ACP, 0, acp.GetData(), -1, p, n);
s.ReleaseBuffer(); |
LPCSTR acp = ...;
int n = ::MultiByteToWideChar(CP_OF_YOUR_CHOICE, 0, acp, -1, NULL, 0);
CString W s;
LPWSTR p = s.GetBuffer(n);
::MultiByteToWideChar(CP_ACP, 0, acp, -1, p, n);
s.ReleaseBuffer();
or CArray<char, char> acp;
// e.g.
// acp.SetSize(n);
// ReadFile(h, acp.GetBuffer(), n, NULL);
then CString s(acp.GetData());
or CString s;
int n = ::MultiByteToWideChar(CP_ACP, 0, acp.GetData(), -1, NULL, 0);
LPWSTR p = s.GetBuffer(n);
::MultiByteToWideChar(CP_ACP, 0, acp.GetData(), -1, p, n);
s.ReleaseBuffer(); |
| Converting To ê |
Converting From è |
Unicode character stream |
| CStringA (CP_ACP) |
CStringW stream = ...;
CStringA s(stream);
or LPCWSTR stream = ...;
CStringA s(stream);
or LPCWSTR stream = ...;
int n = ::WideCharToMultiByte(CP_ACP, 0, stream, -1, NULL, 0, NULL, NULL);
CStringA s;
LPSTR p = s.GetBuffer(n);
::WideCharToMultiByte(CP_ACP, 0, stream, -1, p, n, NULL, NULL);
s.ReleaseBuffer();
or CStringW stream = ...;
int n = ::WideCharToMultiByte(CP_ACP, 0, stream, -1, NULL, 0, NULL, NULL);
CStringA s;
LPSTR p = s.GetBuffer(n);
::WideCharToMultiByte(CP_ACP, 0, stream, -1, p, n, NULL, NULL);
s.ReleaseBuffer(); |
| CStringA (non-CP_ACP) |
LPCWSTR stream = ...;
int n = ::WideCharToMultiByte(CP_OF_YOUR_CHOICE, 0, stream, -1, NULL, 0, NULL, NULL);
CStringA s;
LPSTR p = s.GetBuffer(n);
::WideCharToMultiByte(CP_OF_YOUR_CHOICE, 0, stream, -1, p, n, NULL, NULL);
s.ReleaseBuffer();
or CStringW stream = ...;
int n = ::WideCharToMultiByte(CP_OF_YOUR_CHOICE, 0, stream, -1, NULL, 0, NULL, NULL);
CStringA s;
LPSTR p = s.GetBuffer(n);
::WideCharToMultiByte(CP_OF_YOUR_CHOICE, 0, stream, -1, p, n, NULL, NULL);
s.ReleaseBuffer();
|
| CStringW |
LPCWSTR stream = ...;
CStringW s(stream)
or LPCWSTR stream = ...;
CStringW s = stream; |
| CString (VS6, ANSI mode) |
LPCWSTR stream = ...;
int n = ::WideCharToMultiByte(CP_ACP, 0, stream, -1, NULL, 0, NULL, NULL);
CStringA s;
LPSTR p = s.GetBuffer(n);
::WideCharToMultiByte(CP_ACP, 0, stream, -1, p, n, NULL, NULL);
s.ReleaseBuffer();
or CArray<WCHAR, WCHAR> stream;
// e.g.,
// stream.SetSize(n);
// ReadFile(h, stream.GetData(), n * sizeof(WCHAR), NULL);
int n = ::WideCharToMultiByte(CP_ACP, 0, stream.GetData(), -1, NULL, 0, NULL, NULL);
CString s;
LPSTR p = s.GetBuffer(n);
::WideCharToMultiByte(CP_ACP, 0, stream.GetData(), -1, p, n, NULL, NULL);
s.ReleaseBuffer(); |
| CString (VS6, Unicode mode) |
LPCWSTR stream = ...;
CString s(stream);
or LPCWSTR stream = ...;
CString s;
s = stream;
or CString stream;
// e.g.
// ReadFile(h, stream.GetBuffer(n), n * sizeof(WCHAR), NULL);
// stream.ReleaseBuffer(); |
| Converting To ê |
Converting From è |
CStringA |
CStringW |
| 8-bit characters ACP |
CStringA s = ...;
LPCSTR p = (LPCSTR)s; |
CStringW stream;
CStringA s(stream);
or CStringW stream;
CStringA s;
int n = ::WideCharToMultiByte(CP_ACP, 0, stream, -1, NULL, 0, NULL, NULL);
CStringA s;
LPCSTR p = s.GetBuffer();
::WideCharToMultiByte(CP_ACP, 0, stream, -1, p, n, NULL, NULL);
s.ReleaseBuffer(); |
| 8-bit characters non-ACP |
CStringA s = ...;
LPCSTR p = (LPCSTR)s; |
CStringW stream;
CStringA s;
int n = ::WideCharToMultiByte(CP_OF_YOUR_CHOICE, 0, stream, -1, NULL, 0, NULL, NULL);
CStringA s;
LPCSTR p = s.GetBuffer();
::WideCharToMultiByte(CP_OF_YOUR_CHOICE, 0, stream, -1, p, n, NULL, NULL);
s.ReleaseBuffer(); |
| Unicode Characters |
CStringA s = ...;
CStringW stream(s);
or CStringA s = ...;
int n = MultiByteToWideChar(CP_ACP, 0, (LPCSTR)s, -1, NULL, 0);
CArray<WCHAR, WCHAR> stream;
stream.SetSize(n);
MultiByteToWideChar(CP_ACP, 0, (LPCTSTR)s, -1, stream.GetData(), 0); |
CStringW stream;
...(LPCWSTR)stream...; |
UTF-7 and UTF-8 in CStrings 
In the above examples, the CP_OF_YOUR_CHOICE could be reasonable CP_UTF7 or CP_UTF8. In this case, life gets more than a little strange. You are now working in the domain of Multi-byte Character Sets (MBCS). The significance here is that you no longer have a 1:1 mapping between characters in the string and characters of the character set. In MBCS, it might take two, three, or four characters to represent a single glyph. You cannot predict in advance how many characters are used.
In UTF-8, the most common representation used for Unicode-as-8-bit-sequences, the high-order bit is set on the first and subsequent characters of a multicharacter sequence. You cannot iterate across a string picking up "characters" because you might get the interior representation of a character sequence. Instead, you must iterate using the MBCS support.
| Character value |
UTF-16 |
UTF-8 Byte 1 |
UTF-8 Byte 2 |
UTF-8 Byte 3 |
UTF-8 Byte 4 |
| 000000000x6x5x4x3x2x1x0 |
000000000x6x5x4x3x2x1x0 |
0x6x5x4x3x2x1x0 |
|
|
|
| 00000y4y3y2y1y0x5x4x3x2x1x0 |
00000y4y3y2y1y0x5x4x3x2x1x0 |
110y4y3y2y1y0 |
10x5x4x3x2x1x0 |
|
|
| z3z2z1z0y5y4y3y2y1y0x5x4x3x2x1x0 |
z3z2z1z0y5y4y3y2y1y0x5x4x3x2x1x0 |
1110z3z2z1z0 |
10y5y4y3y2y1y0 |
10x5x4x3x2x1x0 |
|
| u4u3u2u1u0z3z2z1z0y5y4y3y2y1y0x5x4x3x2x1x0 |
110110w3w2w1w0z3z2z1z0y5y4 +
110111y3y2y1y0x5x4x3x2x1x0 |
11110u4u3u2* |
10u1u0z3z2z1z0 |
10y5y4y3y2y1y0 |
10x5x4x3x2x1x0 |
| |
*Note that u4u3u2u1u0 == w3w2w1w0 + 1. Consult The Unicode Standard, Section 3.7, "Surrogates" |
If you are simply assigning strings and manipulating them as entire entities, then UTF-8 and other MBCS encodings pose no problem. However, these strings cannot be examined a character-at-a-time without using the special MBCS functions to "advance to next character", and they cannot be passed as arguments to kernel functions that expect LPC[T]STR values; instead you will have to convert them to Unicode and use that string as the argument. Otherwise, filenames and other things that use string names will end up with erroneous representations. At the moment, I have declared that MBCS is outside the scope of this essay.
There are two forms of ATL String support; those conversions supported by VS6, and those supported by VS.NET. To get these, you must include the ATL support header in your compilation, most commonly in stdafx.h:
#include <afxpriv.h>
The functions are summarized as currenttype2newtype. Thus A2W converts an ANSI string to a Unicode string; T2A converts whatever the current string type is to ANSI. These all allocate a new buffer for the string, which is why I did not use them in the section about Unicode-ANSI conversions. Nonetheless, they are often easiest to use if performance is not a critical issue. Note that conversions down to ANSI will use the current codepage selected for the running thread to do the conversion.
This table is not intended to be comprehensive; it s just the most commonly-used conversions. Consult the MSDN for the complete set of rules. As usual, T is interpreted as A in ANSI applications and W in Unicode applications. The qualifier C indicates a const result.
| A2T |
A2W |
A2CT |
A2CW |
| W2A |
W2T |
W2CA |
W2CT |
| T2A |
T2W |
T2CA |
T2CW |
In VS6, the USES_CONVERSION macro must be called in any function that uses these to avoid compiler warnings. This is not needed in VS.NET. Consult also Microsoft's Technical Note TN059: Using MFC MBCS/Unicode Conversion Macros.
For example, in VS6, to convert a CString to an LPCWSTR, you could do
USES_CONVERSION
CString s = ...;
LPCWSTR p = T2W(s);
SomeAPIThatWantsW(p, ...);
The string that is created will be freed up when the function exits
Summary
These are just some of the techniques for using CString. I use these every day in my programming. CString is not a terribly difficult class to deal with, but generally the MFC materials do not make all of this apparent, leaving you to figure it out on your own.
http://www.flounder.com/cstring.htm#char%20*%20to%20CString

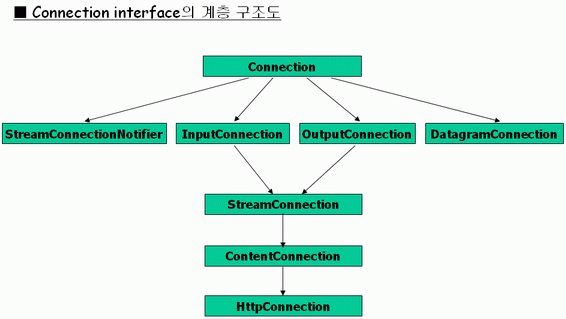
 rom the earliest days of J2ME, network connectivity has been a central focus of the design. So much so that a generic architecture, referred to as the Generic Connection Framework (GCF), was created to standardize not only how applications create network connections but the associated connection interfaces device manufacturers must implement. The GCF is a fundamental part of J2ME and is available to all application profiles including
rom the earliest days of J2ME, network connectivity has been a central focus of the design. So much so that a generic architecture, referred to as the Generic Connection Framework (GCF), was created to standardize not only how applications create network connections but the associated connection interfaces device manufacturers must implement. The GCF is a fundamental part of J2ME and is available to all application profiles including