여러 stream 데이터를 하나의 데이터로 join해 준다면 얼마나 좋을까?
이슈는 상태(state)를 관리해야 하기에 메모리 이슈가 있다.
yelp는 mjoin 알고리즘을 열심히 작업 중이다..
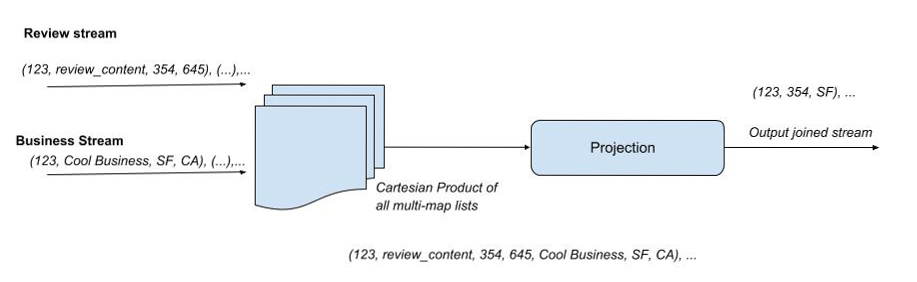
큐의 스트림처리 방식으로는 stream stream-join이라는 개념이 있다.
apache spark에서는 watermark를 활용한다.
https://databricks.com/blog/2018/03/13/introducing-stream-stream-joins-in-apache-spark-2-3.html
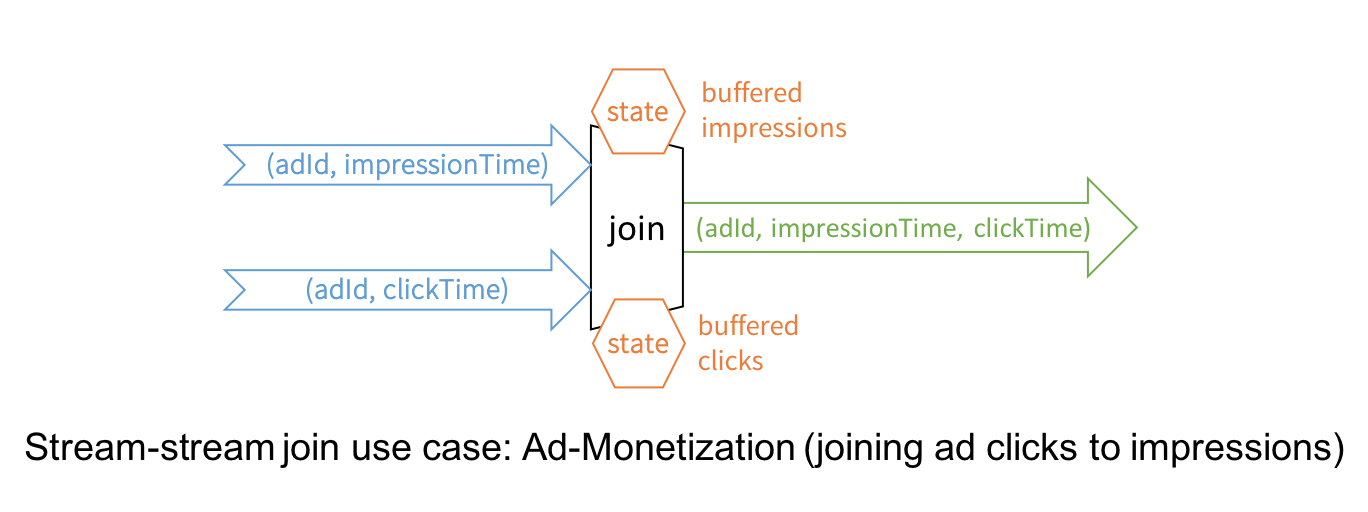
https://dzone.com/articles/spark-stream-stream-join
https://blog.codecentric.de/en/2017/02/crossing-streams-joins-apache-kafka/
메모리 이슈가 있고 역시 타임아웃 이슈가 있어서 완벽히 진행하려면..
데이터를 스토리에 쌓고. 계속 데이터가 도착할 때마다 스토리지를 호출해 데이터가 다 들어올 때까지 쿼리를 날리는 수 밖에 없는 것 같다..
'kafka' 카테고리의 다른 글
| kafka connect 설정 주의 사항 (0) | 2019.04.04 |
|---|---|
| kafka connect Creation of database history topic failed, please create the topic manually / TimeoutException 에러 (0) | 2019.03.19 |
| [펌] kafka burrow api (0) | 2018.11.20 |
| [kafka] enable.auto.commit , auto.commit.interval.ms (0) | 2018.10.22 |
| [kafka] lag 생긴다고 파티션 추가하는 것에 대해 (0) | 2018.08.31 |




