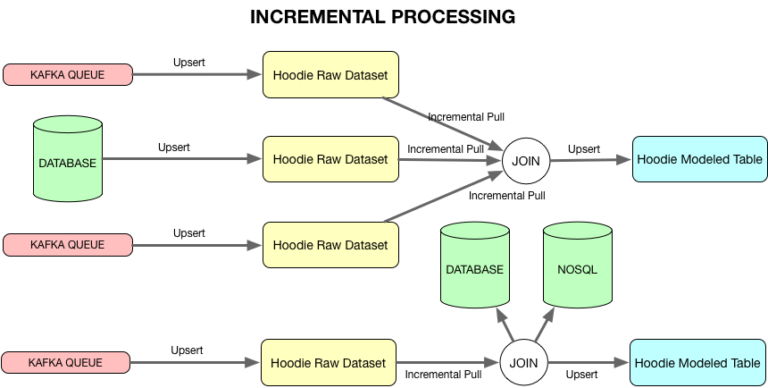
이게 개념적으로 kappa 아키텍처 (보통 우리가 쓰는 lamba 아키텍처의 다음 버전, incremtal )으로
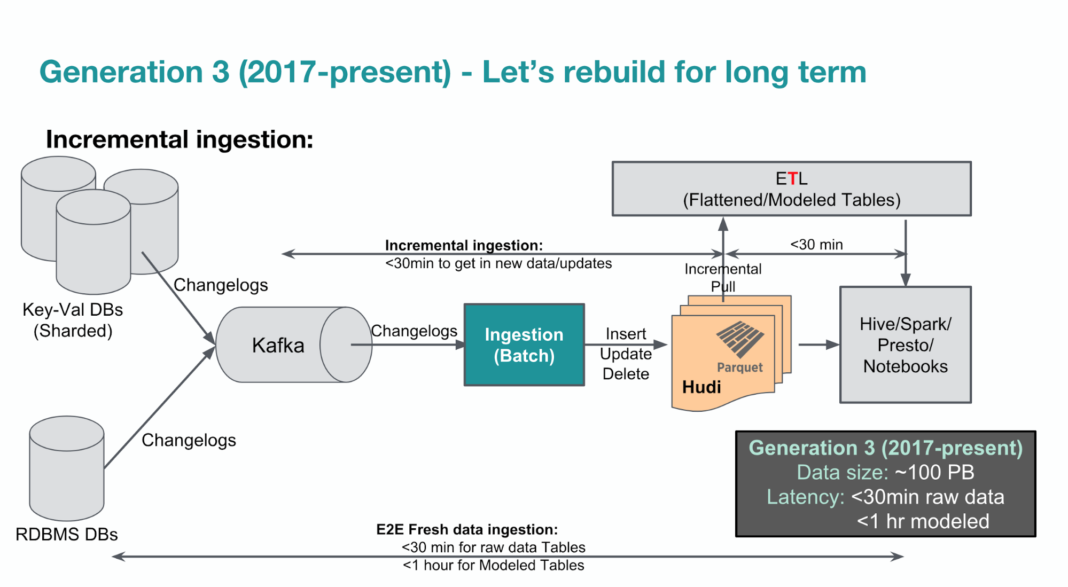
HDFS에 metadata, index, data를 Spark 라이브러리로 구현한 오픈 소스(https://github.com/uber/hudi)이다.
스키마 이슈를 풀기 위해 avro를 사용하고 컬럼 기반의 최적화된 성능을 보장하기 위해 parquet를 사용다. 읽을 때는 컬럼 단위로 읽으니 Scan에 최적화된 Parquet, 저장할 때는 스키마 이슈없고 row단위로 저장하는 Avro를 사용한다. 컴파일 병렬화, 쿼리 병렬화, HDFS의 파일 이슈(쿼터)를 해결하기 위해 HDFS 블록 크기로 저장한다.
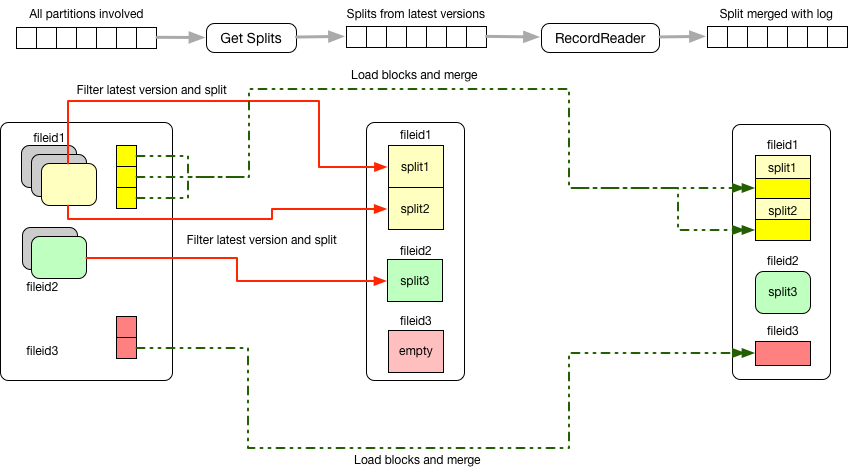
저장할 때 데이터를 정확히 partition 단위로 저장하고, HDFS 블록 크기만큼 채워서 저장한다. 그런식으로 계속 저장한다. 데이터의 변경은 bloom filter로 미리 저장한 위치를 빨리 찾도록 변경된 데이터를 추가하는 방식을 사용하고 있다.
compaction은 시간제한이 걸려 있고 몇 분마다 비동기로 진행한다. 이때 compaction과 변경이 걸리면 이슈가 되니 lock을 zookeeper로 걸어 사용한다.
앤서블 2.4 버전 이전에는 앤서블 실행시 하나의 볼트 암호만 사용할 수 있었었지만 2.4 버전 이후부터 다중 볼트 암호를 사용하여 지원해 --vault-id를 여러 번 제공할 수 있다. 그러나 --vault-id 옵션은 Ansible 2.4 이전 버전을 지원하지 않는다.
여러 볼트 암호가 제공된 경우 기본적으로 앤서블은 커맨드 라인에서 제공된 순서대로 각 볼트 암호를 시도하여 볼트 내용을 해독할 것이다.
예를 들어 특정 파일에 읽은 'dev' 암호를 사용해 'prod' 암호를 입력하라는 메시지를 표시하려면 다음과 같이 사용할 수 있다.
19/01/17 19:42:45 INFO DAGScheduler: Job 1 failed: count at FirstSparkSample.scala:21, took 0.194101 s
Exception in thread "main" org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 2.0 failed 1 times, most recent failure: Lost task 0.0 in stage 2.0 (TID 22, localhost, executor driver): java.lang.NoSuchMethodError: net.jpountz.lz4.LZ4BlockInputStream.<init>(Ljava/io/InputStream;Z)V